So, i'm using examine for umbraco for my website search. So far so good, all results are showing ok.
The problem is when the search terms have accents, for example: logística (its logistics if you're wondering).
If i search with the í, no problem, but if i try with i (logistica) it doesn't find anything. How can make the search Accent Insensitive? I've seaching for hours in here and google, but i didn't find a solution (maybe it's beacause i've got only 3 hours of bed time).
If creating this library and copying over to the bin did you have todo anything else? Or does lucene indexer know what to do by loading up the analyzer becuase it inherits from Analyzer?
I forgot to post above the change in the configuration file (config/ExamineSettings.config).
After you place the assembly in bin, you have to change the analyzer in the Examine settings (I'm only posting my providers, don't delete the the umbraco providers):
Before
<Examine> <ExamineIndexProviders> <providers> <!-- ... snipp of the providers default of umbraco... -->
</ExamineIndexProviders> <ExamineSearchProvidersdefaultProvider="InternalSearcher"> <providers> <!-- ... snipp of the providers default of umbraco... -->
Can you post the links to the Lucene Java docs? Yesterday I went there, but i didn't find anything useful for a noob like me. I think i'm loosing my google it skills...
Nice blog by the way ;) It help me to understand what i had to do for this analyzer
I've tried your solution and it worked great :)
In my case it had a minor issue. Although i wanted to do exactly has you've done, I had to add extra functionality to be able to search for the same word with and without the accent.
For instance, logística and logistica did not returned the same results, due to the indexer not containing the accent.
For being able to give the same results for both words, in my case I've added:
public string RemoveDiacritics(string input) { // Indicates that a Unicode string is normalized using full canonical decomposition. string inputInFormD = input.Normalize(NormalizationForm.FormD); var sb = new StringBuilder();
Just wanted to say: Thank you guys! This solved my case for a site where I had to implement searching for Greek places;-) I had to use both Berto's analyzer mod and Nuno's RemoveDiacritics. Saved my day!
You using greek analyser? Also are you doing wildcard searches? Reason i ask is if you are using analyser it should get ascii folded. When you query if you do not do wilcard then it will also ascii fold and search should work.
I found if i was doing wildcard for say germany then any word with umlaut was not working. This is becuase in index its ascii folded. However when querying it was not ascii folded.
That error can be misleading. You have another issue somewhere with your index and settings config files. I would double check those. Also try commenting out the CiaiAnalyser one does that cause the site to load. If so then you have some issue with that part of the config.
Does umbraco use lucene on backoffice search. The same problem exists on the backoffice content search I' ve tried the CIAIAnalyser solution, however it have made no difference.
The problem occurs on the Turkish I character. When I searched content it sends an ajax request like this:
GET /umbraco/backoffice/UmbracoApi/Content/GetChildren?id=1164&pageNumber=1&pageSize=10&orderBy=sortOrder&orderDirection=Ascending&orderBySystemField=true&filter=seç
So I downloaded the source code and examine the controller. Probably it does not use examine, it brings results from db.
Any other solution or content searcher plugin you can offer would be great.
Examine and accents (for portuguese language)
Hi!
So, i'm using examine for umbraco for my website search. So far so good, all results are showing ok.
The problem is when the search terms have accents, for example: logística (its logistics if you're wondering).
If i search with the í, no problem, but if i try with i (logistica) it doesn't find anything. How can make the search Accent Insensitive? I've seaching for hours in here and google, but i didn't find a solution (maybe it's beacause i've got only 3 hours of bed time).
Thx
So, after mutch digging, reflector came to the rescue (and a good friend that had all the ideias).
the lucene documentation is inexistence or very, very hard to find, if you know where it is, please post it
I just leave my solution for the problem, that turned out to be very easy, if i'm doing it wrong or you know a better way, please share it.
I create a Class Library Project, Added the reference to Lucene.net and created the following class (copy-paste of my cs file):
It's mostly a copy of the StandartFilter in Lucene.net assembly, but using a difrente filter. CIAI is for Case Insensitive, Accent Insensitive
Happy coding!
Berto
Berto,
If creating this library and copying over to the bin did you have todo anything else? Or does lucene indexer know what to do by loading up the analyzer becuase it inherits from Analyzer?
Many thanks
Ismail
Hi Ismail,
I forgot to post above the change in the configuration file (config/ExamineSettings.config).
After you place the assembly in bin, you have to change the analyzer in the Examine settings (I'm only posting my providers, don't delete the the umbraco providers):
Before
After
The only change is the analyzer keyword, where you change it to your assmebly
Berto,
Brilliant post no doubt will prove to be very useful for people doing non english searching.
Regards
Ismail
Refer to the Lucene Java docs, it's just as useful because there are identical APIs.
Also, the StandardAnalyzer (and other default Lucene analyzers) are all for the English language, so yes you do need to write your own.
On an interesting note I believe Manning has a sale on today for the Lucene in Action Second Edition book (which I have a copy of and it's awesome)
Hi Slace,
Can you post the links to the Lucene Java docs? Yesterday I went there, but i didn't find anything useful for a noob like me. I think i'm loosing my google it skills...
Nice blog by the way ;) It help me to understand what i had to do for this analyzer
Here's the 2.9.2 docs - http://lucene.apache.org/java/2_9_2/api/all/index.html
That's the latest version ported to Lucene.Net
Hi Berto.
Excellent post about Examine/Lucene.
I've tried your solution and it worked great :)
In my case it had a minor issue. Although i wanted to do exactly has you've done, I had to add extra functionality to be able to search for the same word with and without the accent.
For instance, logística and logistica did not returned the same results, due to the indexer not containing the accent.
For being able to give the same results for both words, in my case I've added:
This helper function is used on the keyword being searched to remove all accents from it, and to be able to give the same results to both words.
Hope that everyone has understood the issue, and that this helps :)
Cheers!
Hi Nuno! A Portuguese in these forum!!!!! Ta a ver que não encontrava nenhum ;)
I think i didn't had that problem (i have to check it...), but either way, here it is my remove diacritics (it's an extension method)
I'm going to check my search function to see if i had to use it...
Aquele Abraço!
Berto
Just wanted to say: Thank you guys! This solved my case for a site where I had to implement searching for Greek places;-) I had to use both Berto's analyzer mod and Nuno's RemoveDiacritics. Saved my day!
Bendik,
You using greek analyser? Also are you doing wildcard searches? Reason i ask is if you are using analyser it should get ascii folded. When you query if you do not do wilcard then it will also ascii fold and search should work.
I found if i was doing wildcard for say germany then any word with umlaut was not working. This is becuase in index its ascii folded. However when querying it was not ascii folded.
Regards
Ismail
Hi,
I am getting this error
Unable to cast object of type 'MassiveLuceneAnalyser.CiaiAnalyser' to type 'Lucene.Net.Analysis.Analyzer'.
Thanks
Harsheet,
What is MassiveLuceneAnalyser.CiaiAnalyser something custom?
Regards
Ismail
Hi,
Its the class library I created.
Harsheet,
Can you paste your examinesettings.config file. Looks like you may have something incorrect there?
Also at what point do you get the error when the site loads?
There error states
But you have
May be case issue?
Regards
Ismail
Hey, its a typo actually. Its CiaiAnalyser everywhere in my code. But still I am getting an error
Another problem is that I am not able to do this.
tokenizer.SetMaxTokenLength(255);
One more error is coming. See the screenshot attached.
Thanks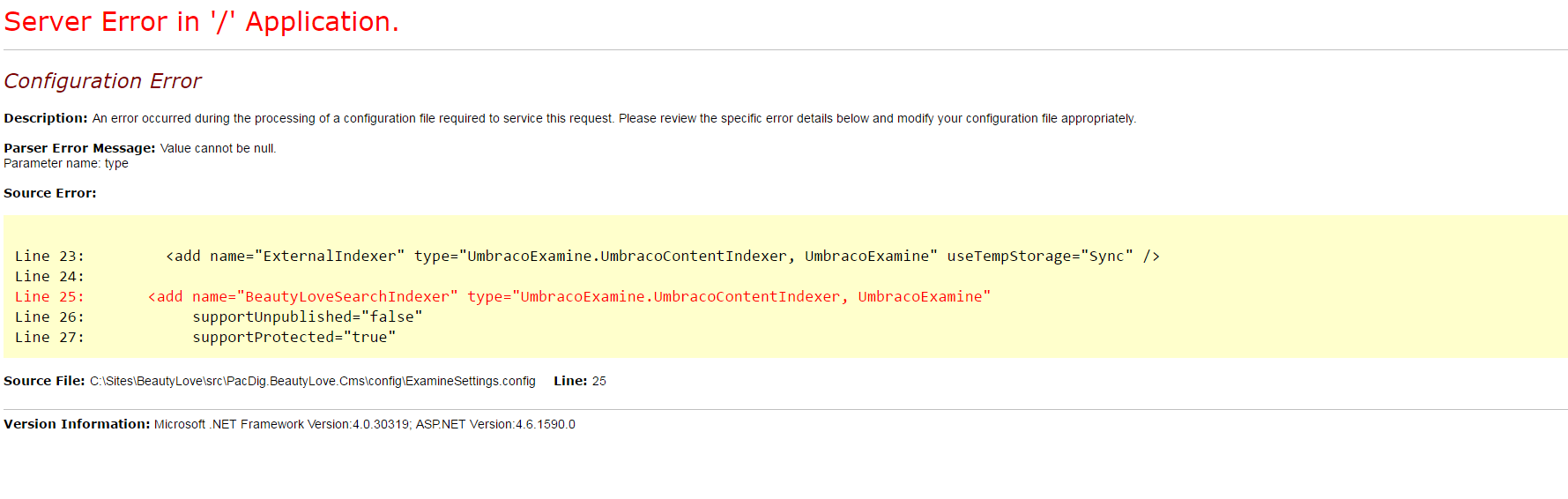
Harsheet,
That error can be misleading. You have another issue somewhere with your index and settings config files. I would double check those. Also try commenting out the CiaiAnalyser one does that cause the site to load. If so then you have some issue with that part of the config.
Regards
Ismail
Hi Berto, i know this is a very old post, yet i'm trying to implement the solution that you and Nuno show and i've the following exception.
Provider must implement the class 'Examine.Providers.BaseSearchProvider'.
my custom provider
{ public class CIAIAnalyser : StandardAnalyzer { public CIAIAnalyser() : base(Lucene.Net.Util.Version.LUCENE24, StopAnalyzer.ENGLISHSTOPWORDSSET) { }
}
and finally examine settings.
I'm having problem with this search terms as well, does it work with .TypedSearch("string") or do I need to use SearchCriteria?
EDIT: Made a post about it: https://our.umbraco.org/forum/extending-umbraco-and-using-the-api/86765-umbracotypedsearch-using-searchterms-with-accents-other-languages#comment-274995
Hello all,
Does umbraco use lucene on backoffice search. The same problem exists on the backoffice content search I' ve tried the CIAIAnalyser solution, however it have made no difference. The problem occurs on the Turkish I character. When I searched content it sends an ajax request like this:
The problem occurs on the Turkish I character. When I searched content it sends an ajax request like this:
GET /umbraco/backoffice/UmbracoApi/Content/GetChildren?id=1164&pageNumber=1&pageSize=10&orderBy=sortOrder&orderDirection=Ascending&orderBySystemField=true&filter=seçSo I downloaded the source code and examine the controller. Probably it does not use examine, it brings results from db.
Any other solution or content searcher plugin you can offer would be great.
Edit: Stackoverflow Link of my question
is working on a reply...
This forum is in read-only mode while we transition to the new forum.
You can continue this topic on the new forum by tapping the "Continue discussion" link below.