We now have some serious problems with our load balanced front end servers. once in a while, they all of a sudden use 25s to answer a call for the API we have created. And it all starts to go really bad, and it'll get quicker again after some minutes. And given that Umbraco serves the front pages for seven webshops, this has gotten a bit important :)
That was the abstract, let's describe the environment a bit:
So we have five servers, one admin that is set as master by code, and four front end servers (flexible load balance) set as slave and the ones that answers the web application that runs (about 40 servers).
The API is getting a published page at root by name, then picks the first node of a given doctype, then at last an ID given from a property on the previous selected node. and convert this to a json that suits our needs.
Most of the time, it answers the webapp at less than 14ms, which is fantastic.
But some times it spends 25 seconds to answer.
We have been using New Relic to have a look at this, and found some interesting stuff.
We can see that there is something going on with ResolveRequestCache and some application code after umbracocacheinstructions sql select. yeah, look at image.
So I looked into the Umbraco log and saw that, yes, there has been a publish right before this happened. And a deeper dive telle me that everytime it got slow, there was a publish. But not everytime a publish has happened it gets slow. so yeah.... bah.
We looked deeper down in the report and looked at the server. And the memory usage isn't that bad, but the CPU. The CPU jumps to 30%, which will be ca. one core of the four the server has. And by looking one more step, we can see that the IO increases as well.
SO, we have narrowed the theory down to:
A publish is made on admin
when one of the four frontend servers gets a request, it sees that it needs to update it's cache
Read from SQL and loads creates the XML and put it in it's cache, and then writes the umbraco.config
Something dodgy is then happening and slows it down when writing umbraco.config, because of the IO report.
What we HAVE tried, is to set ContinouslyUpdateXmlDiskCache to false to perhaps make it write the config file async, but that really made a mess on the servers and all of a sudden we got a couple of days old pages showing instead of the one that should be present and some of the pages was published but not in cache, so after a lot of yelling from the marketing department, we turned it back to true. :)
Oh, yeah, we run 7.4.1 in production, I have now upgraded to 7.5.3 but it's not in production yet, it's in DEV in the hands of QA.
If you are still reading, I really want to thank you for doing so :)
Anyone have any ideas for what we can do to fix this?
In the New Relic capture above, what would the (?) marks on the red lines mean? Any chance it can give more details about what's happening there? I am not 100% familiar with those reports: are the "4 fast method call" part of the above "Applicationcode"?
36MB isn't such a big XML cache file. And the writing of the file is asynchronous in any case so it should not be of any importance. What is synchronous is the update of the in-memory XML cache, which you cannot prevent somehow.
If one single document has been published, then the other nodes in the LB setup need to load that document from DB (hence the cmsContentVersion/cmsPropertyData SQL queries). Should happen once per document and then it is cached. Would be interesting to know, in your case, whether 3 documents were published.
But those queries do not seem to take so much time according to NewRelic. Still trying to figure out what happens in the "red" bars...
The ? on the lines with red bars indicates that it can not dig any further down. Might it be code from an external library?
The 4 fast method calls is the next four calls, sql stuff.
Actually, I think I saw on one log when we had this issue, that there was four pages that was published very rapidly. And there is no slowness during the publish as I'm aware of, but I'm not sure, I'll contact one of the super users and ask if there might be 25s load time when saving and publishing.
@jeroen: 15mb is "biggish" umbraco.config but not "that" big IMHO. how many nodes would that be?
Few extra Q: is the slowness on the slave servers, or also at the time of publish on the master? What's strange is that Vidar mentions slowness on his slaves but not that publishing in itself is especially slow.
Trying to repro here... but if you already have a site where you can repro it'd be great if you can run it under some kind of profiler (dotTrace...)
No it's not that big. Just wanted to report that we could be having similar issues. There are about 9000 content nodes, but some are really big with a lot of Vorto content.
Our users usually alerts me if they experience mush slowness, but they might not if it's only once in a while, but I'll contact them and ask. The reports we are looking at here is from one of the frontend servers.
Regarding reproduction. I got to copy the database from production down to test, and ran a couple of simple tests. It's pretty stable on 14ms, but if I do a couple of rapid publishes, it increases to 6seconds response time.
I need to solve some bugs in dev after upgrading to 7.5.3 first, but after that I'll run some heavier tests to see if I can stress it more.
@Stephen, if you have the time and would like to look more at it, I can add you to the repo and send you a copy of the DB?
I've managed to recreate it on our test environment.
So what I can see is that when there is a bit of traffic on the site, and if four editors are publishing at the same time, which we can see from the logs happened around at least one of the occurrences.
I've created a little screen cast of the issue as well. :)
After several weeks in production and continuously monitoring the solution, I have not seen any response time yet, to exceed 4 seconds (if I remember correctly) - So I think it's safe to say that upgrading was a solution for this issue. We still see some peaks once in a while that are a bit too high, but not like those we saw before upgrading.
It definitely is related to the cache building procedure, we can clearly see that the servers spends more time to answer during the day when the editors are working and obviously publishing pages. And after 4 o'clock, the response curve flats out at 16ms.
I think it's safe to say that in the way we use this Umbraco instance, the upcoming cache rewrite will be very cool :)
I'm on 7.5.4 and are having similar issues apparently. Mine when it took too long to response. It then shows the below. NewRelic shows that the Resolverequestcache took too long to response not sure why. Any idea anyone?
ERROR umbraco.content - Error Republishing
System.Data.SqlClient.SqlException (0x80131904): A transport-level error has occurred when receiving results from the server. (provider: TCP Provider, error: 0 - The semaphore timeout period has expired.) —> System.ComponentModel.Win32Exception (0x80004005): The semaphore timeout period has expired
at System.Data.SqlClient.SqlConnection.OnError(SqlException exception, Boolean breakConnection, Action`1 wrapCloseInAction)
at System.Data.SqlClient.TdsParser.ThrowExceptionAndWarning(TdsParserStateObject stateObj, Boolean callerHasConnectionLock, Boolean asyncClose)
at System.Data.SqlClient.TdsParserStateObject.ReadSniError(TdsParserStateObject stateObj, UInt32 error)
at System.Data.SqlClient.TdsParserStateObject.ReadSniSyncOverAsync()
at System.Data.SqlClient.TdsParserStateObject.TryReadNetworkPacket()
at System.Data.SqlClient.TdsParserStateObject.TryPrepareBuffer()
at System.Data.SqlClient.TdsParserStateObject.TryReadByteArray(Byte[] buff, Int32 offset, Int32 len, Int32& totalRead)
at System.Data.SqlClient.TdsParserStateObject.TryReadString(Int32 length, String& value)
at System.Data.SqlClient.TdsParser.TryReadSqlStringValue(SqlBuffer value, Byte type, Int32 length, Encoding encoding, Boolean isPlp, TdsParserStateObject stateObj)
at System.Data.SqlClient.TdsParser.TryReadSqlValue(SqlBuffer value, SqlMetaDataPriv md, Int32 length, TdsParserStateObject stateObj)
at System.Data.SqlClient.SqlDataReader.TryReadColumnInternal(Int32 i, Boolean readHeaderOnly)
at System.Data.SqlClient.SqlDataReader.TryReadColumn(Int32 i, Boolean setTimeout, Boolean allowPartiallyReadColumn)
at System.Data.SqlClient.SqlDataReader.GetValueInternal(Int32 i)
at System.Data.SqlClient.SqlDataReader.GetValue(Int32 i)
at petapoco_factory_17(IDataReader )
at Umbraco.Core.Persistence.Database.<Query>d__7`1.MoveNext()
at Umbraco.Core.Persistence.Repositories.ContentRepository.BuildXmlCache()
at Umbraco.Core.Services.ContentService.BuildXmlCache()
at umbraco.content.LoadContentFromDatabase()
which then corrupt the xml cache which breaks the site. Happening on the production. Refreshing the app_pool seems to fix it but it came back from time to time
ERROR Umbraco.Core.UmbracoApplicationBase - An unhandled exception occurred
System.Exception: The Xml cache is corrupt. Use the Health Check data integrity dashboard to fix it.
at Umbraco.Web.PublishedCache.XmlPublishedCache.PublishedContentCache.HasContent(UmbracoContext umbracoContext, Boolean preview)
at Umbraco.Web.PublishedCache.ContextualPublishedCache`1.HasContent(Boolean preview)
at Umbraco.Web.UmbracoModule.EnsureHasContent(UmbracoContext context, HttpContextBase httpContext)
at Umbraco.Web.UmbracoModule.EnsureUmbracoRoutablePage(UmbracoContext context, HttpContextBase httpContext)
at Umbraco.Web.UmbracoModule.ProcessRequest(HttpContextBase httpContext)
at System.Web.HttpApplication.SyncEventExecutionStep.System.Web.HttpApplication.IExecutionStep.Execute()
at System.Web.HttpApplication.ExecuteStep(IExecutionStep step, Boolean& completedSynchronously)
Cache in load balanceed environment
Hi,
We now have some serious problems with our load balanced front end servers. once in a while, they all of a sudden use 25s to answer a call for the API we have created. And it all starts to go really bad, and it'll get quicker again after some minutes. And given that Umbraco serves the front pages for seven webshops, this has gotten a bit important :)
That was the abstract, let's describe the environment a bit:
So we have five servers, one admin that is set as master by code, and four front end servers (flexible load balance) set as slave and the ones that answers the web application that runs (about 40 servers).
The API is getting a published page at root by name, then picks the first node of a given doctype, then at last an ID given from a property on the previous selected node. and convert this to a json that suits our needs.
Most of the time, it answers the webapp at less than 14ms, which is fantastic. But some times it spends 25 seconds to answer. We have been using New Relic to have a look at this, and found some interesting stuff.
We can see that there is something going on with ResolveRequestCache and some application code after umbracocacheinstructions sql select. yeah, look at image.
So I looked into the Umbraco log and saw that, yes, there has been a publish right before this happened. And a deeper dive telle me that everytime it got slow, there was a publish. But not everytime a publish has happened it gets slow. so yeah.... bah.
We looked deeper down in the report and looked at the server. And the memory usage isn't that bad, but the CPU. The CPU jumps to 30%, which will be ca. one core of the four the server has. And by looking one more step, we can see that the IO increases as well.
which will be ca. one core of the four the server has. And by looking one more step, we can see that the IO increases as well.
SO, we have narrowed the theory down to:
What we HAVE tried, is to set ContinouslyUpdateXmlDiskCache to false to perhaps make it write the config file async, but that really made a mess on the servers and all of a sudden we got a couple of days old pages showing instead of the one that should be present and some of the pages was published but not in cache, so after a lot of yelling from the marketing department, we turned it back to true. :)
Oh, yeah, we run 7.4.1 in production, I have now upgraded to 7.5.3 but it's not in production yet, it's in DEV in the hands of QA.
If you are still reading, I really want to thank you for doing so :)
Anyone have any ideas for what we can do to fix this?
BR Vidar Aune Westrum
I'd like to add some more details.
I took a look (I like the sound of "took a look") at the umbraco.config. It was 36 MB, 885 903 lines.
Opened issue http://issues.umbraco.org/issue/U4-9049
In the New Relic capture above, what would the (?) marks on the red lines mean? Any chance it can give more details about what's happening there? I am not 100% familiar with those reports: are the "4 fast method call" part of the above "Applicationcode"?
36MB isn't such a big XML cache file. And the writing of the file is asynchronous in any case so it should not be of any importance. What is synchronous is the update of the in-memory XML cache, which you cannot prevent somehow.
If one single document has been published, then the other nodes in the LB setup need to load that document from DB (hence the cmsContentVersion/cmsPropertyData SQL queries). Should happen once per document and then it is cached. Would be interesting to know, in your case, whether 3 documents were published.
But those queries do not seem to take so much time according to NewRelic. Still trying to figure out what happens in the "red" bars...
Thanks @Stephen for looking into this!
The ? on the lines with red bars indicates that it can not dig any further down. Might it be code from an external library?
The 4 fast method calls is the next four calls, sql stuff.
Actually, I think I saw on one log when we had this issue, that there was four pages that was published very rapidly. And there is no slowness during the publish as I'm aware of, but I'm not sure, I'll contact one of the super users and ask if there might be 25s load time when saving and publishing.
Wow great report Vidar. This situation looks very familiar.
So it seems we are having similar issues. Currently we're at Umbraco 7.4.3.
Hopefully it can be fixed.
Jeroen
@jeroen: 15mb is "biggish" umbraco.config but not "that" big IMHO. how many nodes would that be?
Few extra Q: is the slowness on the slave servers, or also at the time of publish on the master? What's strange is that Vidar mentions slowness on his slaves but not that publishing in itself is especially slow.
Trying to repro here... but if you already have a site where you can repro it'd be great if you can run it under some kind of profiler (dotTrace...)
No it's not that big. Just wanted to report that we could be having similar issues. There are about 9000 content nodes, but some are really big with a lot of Vorto content.
Hi again :)
Our users usually alerts me if they experience mush slowness, but they might not if it's only once in a while, but I'll contact them and ask. The reports we are looking at here is from one of the frontend servers.
Regarding reproduction. I got to copy the database from production down to test, and ran a couple of simple tests. It's pretty stable on 14ms, but if I do a couple of rapid publishes, it increases to 6seconds response time.
I need to solve some bugs in dev after upgrading to 7.5.3 first, but after that I'll run some heavier tests to see if I can stress it more.
@Stephen, if you have the time and would like to look more at it, I can add you to the repo and send you a copy of the DB?
Hi!
I've managed to recreate it on our test environment.
So what I can see is that when there is a bit of traffic on the site, and if four editors are publishing at the same time, which we can see from the logs happened around at least one of the occurrences.
I've created a little screen cast of the issue as well. :)
https://youtu.be/3-tIqJeW4jk
I'm sorry for the poor quality, I was in the believe that my software was capturing full res, but it was set to 720 :(
I'd like to make a little note to this.
Launched 7.5.3 to production today.
Guess what time we pushed it!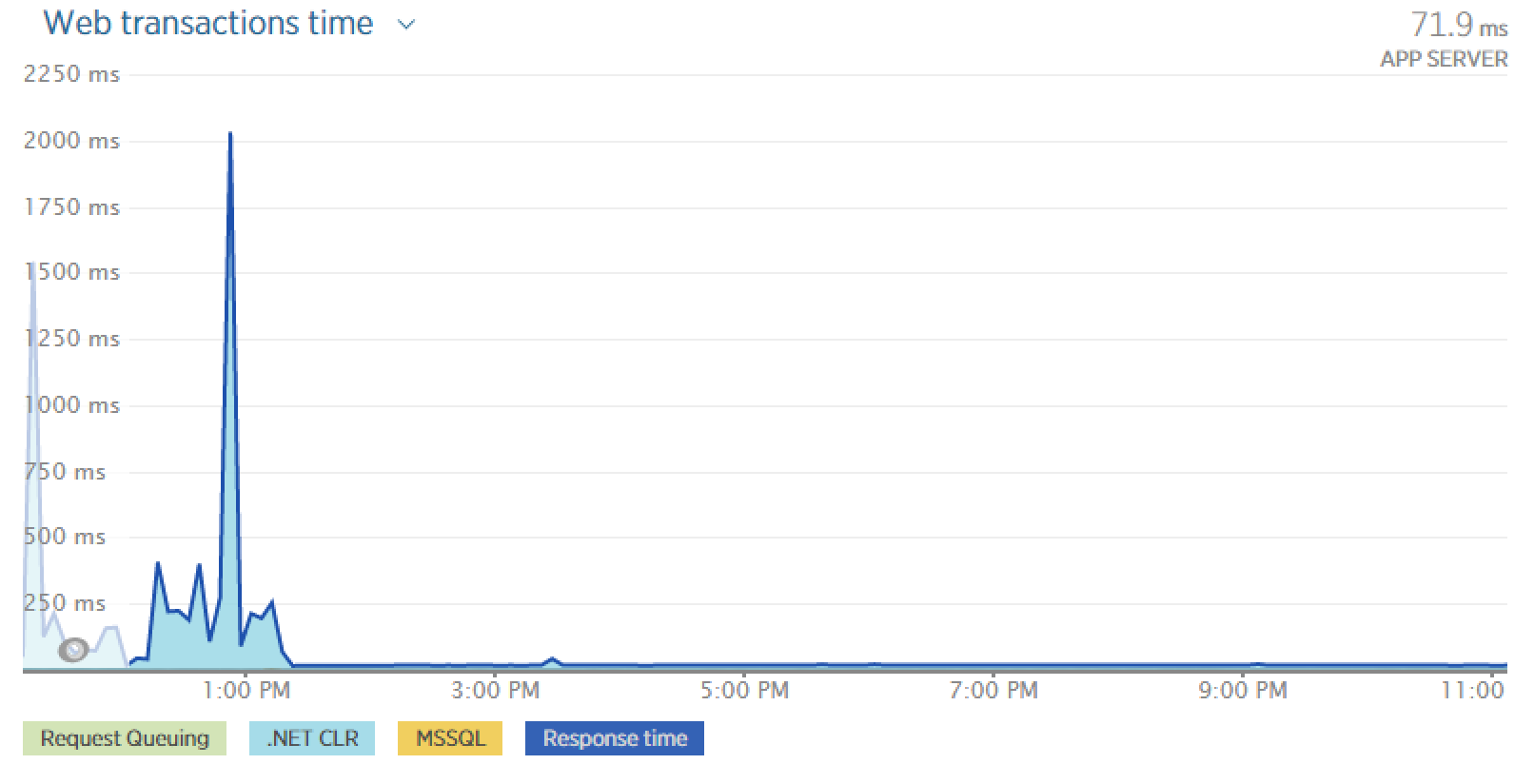
After several weeks in production and continuously monitoring the solution, I have not seen any response time yet, to exceed 4 seconds (if I remember correctly) - So I think it's safe to say that upgrading was a solution for this issue. We still see some peaks once in a while that are a bit too high, but not like those we saw before upgrading.
It definitely is related to the cache building procedure, we can clearly see that the servers spends more time to answer during the day when the editors are working and obviously publishing pages. And after 4 o'clock, the response curve flats out at 16ms.
I think it's safe to say that in the way we use this Umbraco instance, the upcoming cache rewrite will be very cool :)
Thanks again for your effort and reply guys!
I'm on 7.5.4 and are having similar issues apparently. Mine when it took too long to response. It then shows the below. NewRelic shows that the Resolverequestcache took too long to response not sure why. Any idea anyone?
Similar setup here 2 read-only servers which periodically spend seconds talking to Umbraco even on API controllers that don't use Umbraco
Unfortunately we're on 7.5.3 so...
is working on a reply...
This forum is in read-only mode while we transition to the new forum.
You can continue this topic on the new forum by tapping the "Continue discussion" link below.