We have recently used Umbraco PDF searcher plugin in our web application. Somehow the pdf searcher is not returning expected result.
For example, when we pass "Smith" as search term it returns a node list but the score does not look right. We expect the result to be in order of the occurances of "Smith" word within the pdf.
Question : If a pdf contains "Smith" word 15 times will it have higher score than the pdfs containing "Smith" word 10 or 7 times. Or the physical size of the pdf is taken into account? Or there are any other considerations while defining the seach socre? At the moment we don't understand how the pdf search is exactly done by Examine or Lucene.
I have attached an image of our search result.
Thanks in advance.
Umbraco PDF search score
Hello,
We have recently used Umbraco PDF searcher plugin in our web application. Somehow the pdf searcher is not returning expected result.
For example, when we pass "Smith" as search term it returns a node list but the score does not look right. We expect the result to be in order of the occurances of "Smith" word within the pdf.
Question : If a pdf contains "Smith" word 15 times will it have higher score than the pdfs containing "Smith" word 10 or 7 times. Or the physical size of the pdf is taken into account? Or there are any other considerations while defining the seach socre? At the moment we don't understand how the pdf search is exactly done by Examine or Lucene.
I have attached an image of our search result. Thanks in advance.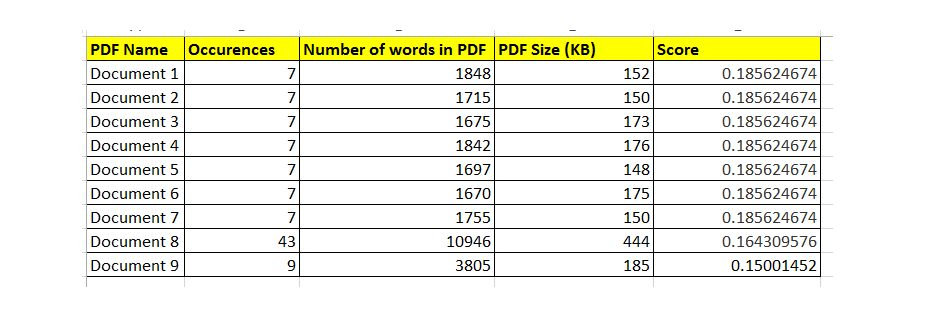
is working on a reply...
This forum is in read-only mode while we transition to the new forum.
You can continue this topic on the new forum by tapping the "Continue discussion" link below.