Hi, I have created a custom index and I am trying to use a custom Lucene Analyzer. My custom analyzer is displayed in the back office (CustomAnalyzer) on screenshot but the code in it is never fired.
Does anyone has been successfull doing this kind of thing ?
Can you show the code of your IndexCreator? That is where you setup the analyser, I have a custom index and I have custom analyser my code looks like:
public class HighQIndexCreator : LuceneIndexCreator
{
public override IEnumerable<IIndex> Create()
{
//we the sectors and practice areas are multi value fields and we want to analyse them
// using keywordanalyser to help with tag searches, eg do not token on space and do not replace stop
//words else any tag with "And" in it wont work
PerFieldAnalyzerWrapper customAnalyzer = new PerFieldAnalyzerWrapper(new StandardAnalyzer(Version.LUCENE_30));
customAnalyzer.AddAnalyzer(HiqhQIndexConstants.IndexFieldAliases.TagPrefix + HiqhQIndexConstants.IndexFieldAliases.Sectors,
new KeywordAnalyzer());
customAnalyzer.AddAnalyzer(HiqhQIndexConstants.IndexFieldAliases.TagPrefix + HiqhQIndexConstants.IndexFieldAliases.PracticeAreas,
new KeywordAnalyzer());
customAnalyzer.AddAnalyzer(HiqhQIndexConstants.IndexFieldAliases.TagPrefix + HiqhQIndexConstants.IndexFieldAliases.Authors,
new KeywordAnalyzer());
var index = new LuceneIndex(HiqhQIndexConstants.ExamineIndexName,
CreateFileSystemLuceneDirectory(HiqhQIndexConstants.ExamineIndexName),
new FieldDefinitionCollection(
new FieldDefinition(HiqhQIndexConstants.IndexFieldAliases.Title, FieldDefinitionTypes.FullTextSortable),
new FieldDefinition(HiqhQIndexConstants.IndexFieldAliases.Description, FieldDefinitionTypes.FullText),
new FieldDefinition(HiqhQIndexConstants.IndexFieldAliases.Content, FieldDefinitionTypes.FullText),
new FieldDefinition(HiqhQIndexConstants.IndexFieldAliases.Contents, FieldDefinitionTypes.FullText),
new FieldDefinition(HiqhQIndexConstants.IndexFieldAliases.PublicationDate, FieldDefinitionTypes.DateTime),
new FieldDefinition(HiqhQIndexConstants.IndexFieldAliases.Url, FieldDefinitionTypes.Raw),
new FieldDefinition(HiqhQIndexConstants.IndexFieldAliases.Author, FieldDefinitionTypes.FullText),
new FieldDefinition(HiqhQIndexConstants.IndexFieldAliases.Authors+"Raw", FieldDefinitionTypes.FullText),
new FieldDefinition(HiqhQIndexConstants.IndexFieldAliases.AuthorEmail,FieldDefinitionTypes.EmailAddress),
new FieldDefinition(HiqhQIndexConstants.IndexFieldAliases.Id, FieldDefinitionTypes.Integer)
),
customAnalyzer);
return new[] { index };
}
}
I studied your code and I thing that I have implemented something similar.
I am pasting below parts of my code. Please note that I am working on Umbraco Cloud 8.5.1.
My index creator
public override IEnumerable<IIndex> Create()
{
return new[]
{
CreateCustomIndex()
};
}
private IIndex CreateCustomIndex()
{
var index = new UmbracoContentIndex(Constants.UmbracoIndexes.WebsiteCustomIndexName,
CreateFileSystemLuceneDirectory(Constants.UmbracoIndexes.WebsiteCustomIndexPath),
new UmbracoFieldDefinitionCollection(),
new CustomLuceneAnalyzer(),
ProfilingLogger,
LanguageService,
new ContentValueSetValidator(true));
return index;
}
My analyzer:
public class CustomLuceneAnalyzer : Analyzer
{
public override TokenStream TokenStream(string fieldName, System.IO.TextReader reader)
{
NormalizeCharMap map = new NormalizeCharMap();
map.Add("ά", "α");
map.Add("έ", "ε");
map.Add("ί", "ι");
map.Add("ό", "ο");
map.Add("ύ", "υ");
map.Add("ή", "η");
map.Add("ώ", "ω");
map.Add("ς", "σ");
map.Add("Ά", "Α");
map.Add("Έ", "ε");
map.Add("Ί", "ι");
map.Add("Ό", "ο");
map.Add("Ύ", "υ");
map.Add("Ή", "η");
map.Add("Ώ", "ω");
StandardTokenizer tokenizer = new StandardTokenizer(Lucene.Net.Util.Version.LUCENE_30, reader);
tokenizer.MaxTokenLength =255;
TokenStream stream = new StandardFilter(tokenizer);
stream = new LowerCaseFilter(stream);
stream= new ASCIIFoldingFilter(stream);
new MappingCharFilter(map, reader);
return stream;
}
}
The goal of the implementation is to achieve search functionality for words with accents and word derivatives in Greek language (e.g. if the keyword is science I want to get results including the word scientific).
I have not tried it on cloud this is on azure webapp. Also with Umbraco 8.3.0
With regards to your problem, I was a little confused with what you are trying to solve. So if the issue is ascii folding i,e searches in greek not working then as long as you are not doing wildcard searches the standard analyser will already ascii flatten for you during indexing and searching and it should all work.
It you are wildcard searching then during searching you could ascii flatten the query then search. I have done this in the past.
Also any reason why you are not using greek analyser?
if the keyword is science I want to get results including the word scientific
This would imply stemming? You could use port stemmer in your custom analyser?
Coming back your original point code not firing, have you tested locally with debugger? does it hit break point? If not could be something todo with composition ordering?
I had this problem with Examine 1.0.2 (maybe it has change in newer versions), and after spending couple of hours investigating this, and digging through Lucene and Examine source code, I came with the following solution.
var analyzer = new PerFieldAnalyzerWrapper(new SuggestionsAnalyzer(Version.LUCENE_30));
var fieldDefinitions = new []{
new FieldDefinition("value", FieldDefinitionTypes.FullText)};
var index = new LuceneIndex("SuggestionsIndex",
CreateFileSystemLuceneDirectory("SuggestionsIndex"),
new FieldDefinitionCollection(fieldDefinitions),
analyzer, null,
new Dictionary<string, IFieldValueTypeFactory>
{
[FieldDefinitionTypes.FullText] = new DelegateFieldValueTypeFactory(n =>
new FullTextType(n, new SuggestionsAnalyzer(Version.LUCENE_30)))
});
return new[] { index };
It really does not matter what analyzer we provide to LuceneIndex, because it will be wrapped with a PerFieldAnalyzerWrapper. This is not a problem by itself, as this wrapper has a default analyzer property. However, Examine will create default analyzers for all field definitions, and add them to the PerFieldAnalyzerWrapper, which results in the default analyzer being never used (if this makes sense to you). I don’t know it this is a bug or design flaw, or maybe I’m getting something wrong, however I think it does not matter what analyzer you pass to the LuceneIndex constructor, it will never be used.
The fix is to provide a custom IFieldValueTypeFactory. The example above sets my SuggestionsAnalyzer for all FieldDefinitionTypes.FullText fields.
V8 : DefaultAnalyzer on custom index
Hi, I have created a custom index and I am trying to use a custom Lucene Analyzer. My custom analyzer is displayed in the back office (CustomAnalyzer) on screenshot but the code in it is never fired.
Does anyone has been successfull doing this kind of thing ?
Thank you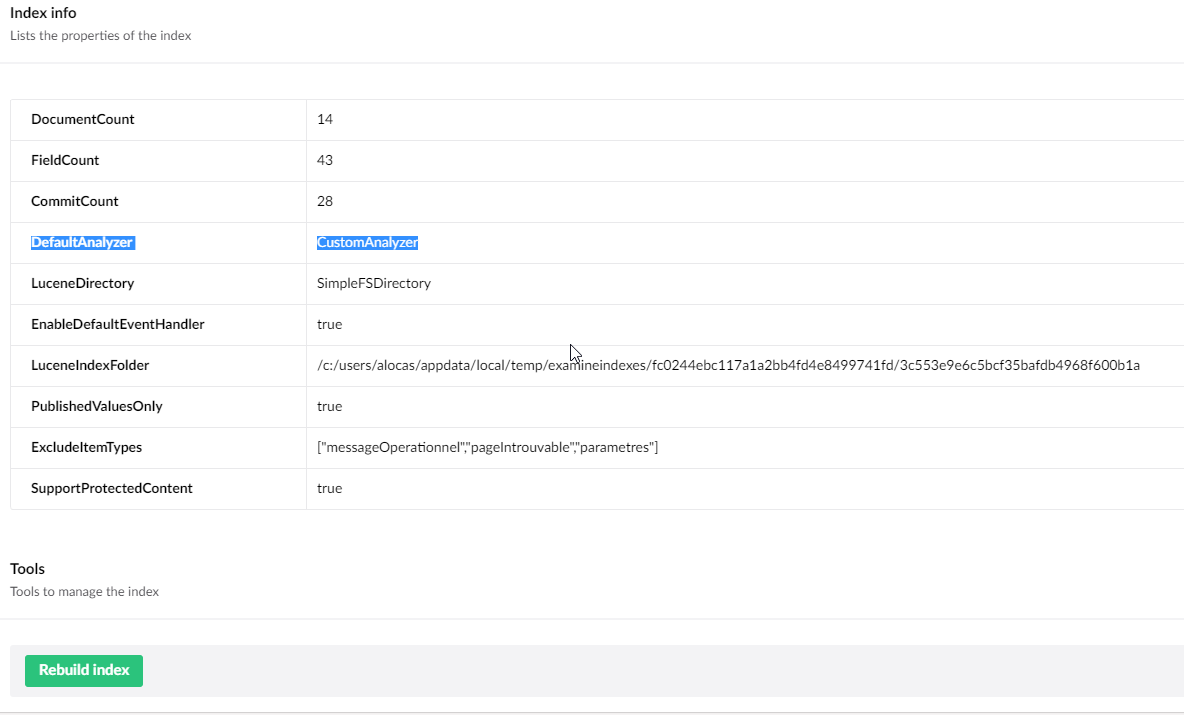
Hello
I am dealing with the same issue.
Did you ever manage to solve it?
Thank you
Hi, I did not solve it. We ended up doing external indexing (with Solr) with our own code, bypassing everything Examine-related.
Can you show the code of your IndexCreator? That is where you setup the analyser, I have a custom index and I have custom analyser my code looks like:
Regards
Ismail
Hello Ismail
I studied your code and I thing that I have implemented something similar.
I am pasting below parts of my code. Please note that I am working on Umbraco Cloud 8.5.1.
My index creator
My analyzer:
The goal of the implementation is to achieve search functionality for words with accents and word derivatives in Greek language (e.g. if the keyword is science I want to get results including the word scientific).
Thank you
Dimitris,
I have not tried it on cloud this is on azure webapp. Also with Umbraco 8.3.0
With regards to your problem, I was a little confused with what you are trying to solve. So if the issue is ascii folding i,e searches in greek not working then as long as you are not doing wildcard searches the standard analyser will already ascii flatten for you during indexing and searching and it should all work.
It you are wildcard searching then during searching you could ascii flatten the query then search. I have done this in the past.
Also any reason why you are not using greek analyser?
https://github.com/apache/lucenenet/tree/3.0.3/src/contrib/Analyzers/El
Regarding your point:
This would imply stemming? You could use port stemmer in your custom analyser?
Coming back your original point code not firing, have you tested locally with debugger? does it hit break point? If not could be something todo with composition ordering?
Hi Axexandre, Did you solve this? Having the same issue, code not firing.
Hi, no I did succeded. Instead we ended up using Solr as our search engine. Good luck
I had this problem with Examine 1.0.2 (maybe it has change in newer versions), and after spending couple of hours investigating this, and digging through Lucene and Examine source code, I came with the following solution.
It really does not matter what analyzer we provide to LuceneIndex, because it will be wrapped with a PerFieldAnalyzerWrapper. This is not a problem by itself, as this wrapper has a default analyzer property. However, Examine will create default analyzers for all field definitions, and add them to the PerFieldAnalyzerWrapper, which results in the default analyzer being never used (if this makes sense to you). I don’t know it this is a bug or design flaw, or maybe I’m getting something wrong, however I think it does not matter what analyzer you pass to the LuceneIndex constructor, it will never be used. The fix is to provide a custom IFieldValueTypeFactory. The example above sets my SuggestionsAnalyzer for all FieldDefinitionTypes.FullText fields.
is working on a reply...
This forum is in read-only mode while we transition to the new forum.
You can continue this topic on the new forum by tapping the "Continue discussion" link below.