"Save" button loading forever on Azure App Service
Hi All,
I have a strange issue when I click the "Save" button to save a document type in the Backoffice. When the site is deployed to azure app service, it shows the loading icon for an extremely long time (i dont know exactly, but it feels like minutes). But if I run out of patients and refresh the window after, say 10 seconds, the changes have actually been persisted even though the button hasn't stopped loading.
When I inspect the network tab, I can see that the PostSave call is eventually getting a gateway timeout on the azure app service, which enables the save button again and shows a back office error. But again, the changes are actually persisted.
When I run the site locally this does not happen. Even when I point my local environment at the same Azure database that the app service uses. So I don't think its a database performance issue.
There is also another behaviour I have seen on application startup that might be related. Locally, the application starts in a few seconds (even when pointed at the Azure database the app service uses). But on the Azure App Service itself, it takes several minutes to start. At a guess, Id say between 5 and 10 minutes.
Any ideas what could be causing this?
FYI, I am using the latest version 9, but this has been happening for some time through all the various RCs and nightly builds
Are you load balanced (i.e. multi-Umbraco-instance)? And even if not, have you configured the server role(s) correctly (single/publisher/subscriber)?
Are you multi-Azure-app-instance?
Are you using Azure SQL or SQL Server or something else?
Are you using uSync?
Which model builder mode are you on?
We haven't deployed a v9 site to Azure yet (only v8), but we run all our Umbracos as load balanced Azure App Services (using SQL Server on an Azure VM on the same internal network) and don't have this problem.
Thanks for the replies guys. Sorry if I didn't give enough info:
Which App Service Plan are you using?
This is our test environment. Its running P2V2 (7GB memory, 420ACU)
Do you see a CPU or memory spike on that plan when saving the document
type?
No, I cant see a CPU spike when saving, nor anything significant while starting up either.
How many documents are using this document type?
It happens on all document types as far as I can tell. Some with as few as 1 document using it. Many of my document types are elements used within blocklists. Not sure if that would make a difference?
Which Azure SQL Database type are you using? (DTU or B, S0, S1, ...)
S4 and utilisation never goes above 3 or 4%
Do you see anything in the logfiles?
Nothing. But ill try increase the log level and see if I see anything else.
Are you load balanced (i.e. multi-Umbraco-instance)? And even if not, have you configured the server role(s) correctly (single/publisher/subscriber)?
Are you multi-Azure-app-instance?
Are you using Azure SQL or SQL Server or something else?
I'm running this on an app service and the app service plan is set not to scale for the moment, so it will only be one instance, but still, you make an interesting point, there are extra network layers that I wont have locally. Let me have a read of the multi-intance documentation and see if there is anything in that.
using SQL Server on an Azure VM on the same internal network)
Yeah, i have had problems with DTU throttling on Azure SQL Databases in the past when running complex queries, which you dont see on SQL server running on a VM. But I see no evidence of that here because all the utilisation charts are very low.
But perhaps I have caused an issue by connecting to the Azure Db from my local environment? I mean, I occasionally connect to the "test environment" azure database from my local machine. So effectively there are 2 instances of the Backoffice using the same Db. I havent had a chance to read the docs about multi-instance, but could that be an issue? But in saying that, if it was an issue, you would expect to see weird behaviour on both Backoffices, but I dont. Just the one hosted on Azure app service.
Its running on Linux too, and my local machine is Windows.
When I increase the log level on the server, I get the following when I save a document type:
Invoking refresher {RefresherType} on local server for message type RefreshByPayload","@l":"Debug","RefresherType":"Umbraco.Cms.Core.Cache.ContentTypeCacheRefresher
Notified {ChangeTypes} for {ItemType} {ItemId}","@l":"Debug","ChangeTypes":"RefreshOther","ItemType":"IContentType","ItemId":18143,"SourceContext":"Umbraco.Cms.Infrastructure.PublishedCache.PublishedSnapshotService","ActionId":"3013ab77-c65d-42c5-a887-07da177d116c","ActionName":"Umbraco.Cms.Web.BackOffice.Controllers.ContentTypeController.PostSave (Umbraco.Web.BackOffice)","RequestId":"0HMC7BR45ABD3:00000016","RequestPath":"/umbraco/backoffice/umbracoapi/contenttype/PostSave
Notified {ChangeTypes} for content {ContentId}","@l":"Debug","ChangeTypes":"RefreshAll","ContentId":0,"SourceContext":"Umbraco.Cms.Infrastructure.PublishedCache.PublishedSnapshotService","ActionId":"3013ab77-c65d-42c5-a887-07da177d116c","ActionName":"Umbraco.Cms.Web.BackOffice.Controllers.ContentTypeController.PostSave (Umbraco.Web.BackOffice)","RequestId":"0HMC7BR45ABD3:00000016","RequestPath":"/umbraco/backoffice/umbracoapi/contenttype/PostSave
{StartMessage} [Timing {TimingId}]","StartMessage":"Loading content from database"
Which seems to then trigger a rake load of these log entries (over 5000, so i think its every node on the site):
Set {kit.Node.Id} with parent {kit.Node.ParentContentId}","@l":"Debug","kit.Node.Id":2117,"kit.Node.ParentContentId":-1,"SourceContext":"ContentStore"
Which, on the face of it seems a bit fishy. But according to the timestamps of the logs and the timing messages, it takes less than a second to complete:
And Id assume that these kinds of thing don't run interactively anyway, right? I mean, I assume if there is some sort of cache re-building going on, it wouldn't block the back office requests.
Saving is actually instant (you could verify this, right? For example in the logs seeing the "save" take place normally when clicking save)
Web UI hangs because PostSave never gets a response from the Umbraco back office APIs, and gets a "gateway timeout" when ARR(?) has timed out
Can you show the "gateway timeout" error, and any strange requests/response before/after? This looks like a communication failure between the web UI and PostSave, so something strictly Azure-infrastructure-related, or web app configuration related.
Yeah, correct. If I wait a couple of seconds and then reload the browser after clicking save, the changes have persisted.
It does feel like a network-y type of issue to me. I cant find any evidence of a performance bottleneck. I have not changed any settings on the app services relating to networking. Its an off-the-shelf .net 5 linux app service, with the deployment centre hooked up to a repo. Thats it.
There are no other network requests going on when I get the gateway timeout. Except this request that polls, but again, this seems normal:
I think I have discovered the issue. I have been working locally a lot more lately, migrating a large amount of data onto the new Umbraco site and I started seeing this behaviour locally too.
Locally, I was able to wait for the server to eventually respond (I obviously don't get the gateway timeout locally) and I could see that our earlier assumptions about the cache building being in a background job were incorrect. The sever eventually responded after the cache building has finished (after like 3 or 4 minutes).
So I started having a look at the source code in this area and I found this comment in PublishedSnapshotService.cs
// In the case of ModelsMode.InMemoryAuto generated models - we actually need to refresh all of the content and the media
// see https://github.com/umbraco/Umbraco-CMS/issues/5671
// The underlying issue is that in ModelsMode.InMemoryAuto mode the IAutoPublishedModelFactory will re-compile all of the classes/models
// into a new DLL for the application which includes both content types and media types.
// Since the models in the cache are based on these actual classes, all of the objects in the cache need to be updated
// to use the newest version of the class.
// NOTE: Ideally this can be run on background threads here which would prevent blocking the UI
// as is the case when saving a content type. Initially one would think that it won't be any different
// between running this here or in another background thread immediately after with regards to how the
// UI will respond because we already know between calling `WithSafeLiveFactoryReset` to reset the generated models
// and this code here, that many front-end requests could be attempted to be processed. If that is the case, those pages are going to get a
// model binding error and our ModelBindingExceptionFilter is going to to its magic to reload those pages so the end user is none the wiser.
// So whether or not this executes 'here' or on a background thread immediately wouldn't seem to make any difference except that we can return
// execution to the UI sooner.
// BUT!... there is a difference IIRC. There is still execution logic that continues after this call on this thread with the cache refreshers
// and those cache refreshers need to have the up-to-date data since other user cache refreshers will be expecting the data to be 'live'. If
// we ran this on a background thread then those cache refreshers are going to not get 'live' data when they query the content cache which
// they require.
So, it seems when you have models builder set to "InMemoryAuto", the caches are rebuilt on the interactive thread. And because I have over 100k documents, its taking several minutes to do this.
It sounds like the simple solution is to change the models builder configuration to another option than "InMemoryAuto", which I will try. But peeking around at the code, Im not sure it will change anything.
The caches are rebuild if this is true:
if (_publishedModelFactory.IsLiveFactoryEnabled())
and the source of this method is:
public static bool IsLiveFactoryEnabled(this IPublishedModelFactory factory)
{
if (factory is IAutoPublishedModelFactory liveFactory)
{
return liveFactory.Enabled;
}
// if it's not ILivePublishedModelFactory we can't determine if it's enabled or not so return true
return true;
}
So according to this, it will always return true, unless the factory is an instance of IAutoPublishedModelFactory. In which case it returns factory.Enabled.
BUT
It looks like there is only one implementation of this interface:
InMemoryModelFactory
and for factory.Enabled
it uses this:
public bool Enabled => _config.ModelsMode == ModelsMode.InMemoryAuto;
So, basically, this is always going to happen, regardless of the models builder config.
Because if i dont set it to "inMemoryAuto" i fall into the else block from earlier "// if it's not ILivePublishedModelFactory we can't determine if it's enabled or not so return true" and if I DO set it to "inMemoryAuto", true is always returned.
I hope I am missing something, but I'll try this out and see what the behaviour is in testing.
So, just to be clear, when you save a document type in development it takes 3-4 minutes with 100k documents? That sounds insane. I've never seen document type save times above a few seconds.
Why would the number of documents matter? It seems like only the amount of document types should matter? How many document types do you have?
Perhaps there is something in your solution that increases the cache rebuild time dramatically?
Other than that, fantastic investigation. Following with great curiousity. :) And it's disappointing that Occam's razor strikes again; the timeout occurred because the save actually did time out.
I think the reason the number of documents matters is because when it forces a cache refresh, it queries all the content, all >100k records, creates a new IPublishedContent for each of them and then saves them all into the content cache. Then it does the same for the media.
The document type save works in a second or two, like you say. It does actually persist the changes. But it looks like it triggers a cache rebuild (which take a few minutes) before it returns a response back to the browser.
I changed to another models builder mode: SourceCodeAuto
Same behaviour.
I figure that the implementation of the IPublishedModelFactory that the site uses needs to implement IAutoPublishedModelFactory but also return false for the Enabled property of the IAutoPublishedModelFactory interface, if I want to turn off this auto cache re-build (see the logic in the posts above).
There is no implementation like this in the source code. Its my opinion that if I set
"ModelsBuilder": {
"ModelsMode": "Nothing"
}
I should get an implementation injected as i described above. But i dont. I get the NoopPublishedModelFactory which does not implement IAutoPublishedModelFactory.
So I made my own one:
public class NoopAutoPublishedModelFactory : IAutoPublishedModelFactory
{
public object SyncRoot { get; } = new object();
public bool Enabled => false;
public IPublishedElement CreateModel(IPublishedElement element) => element;
public IList CreateModelList(string alias) => new List<IPublishedElement>();
public Type MapModelType(Type type) => typeof(IPublishedElement);
public void Reset()
{
}
}
and added it to the serivces after removing all other implementations:
public static IUmbracoBuilder AddNoopAutoPublishedModelFactory(this IUmbracoBuilder builder)
{
while (builder.Services.Any(descriptor => descriptor.ServiceType == typeof(IPublishedModelFactory)))
{
var serviceDescriptor = builder.Services.FirstOrDefault(descriptor => descriptor.ServiceType == typeof(IPublishedModelFactory));
builder.Services.Remove(serviceDescriptor);
}
builder.Services.AddSingleton<IPublishedModelFactory, NoopAutoPublishedModelFactory>();
return builder;
}
Now, when I save a doc type, it doesnt take 3 to 4 minutes and spew out hundreds of thousands of logs, it takes about 25 seconds. and the logs look like this:
[00:20:22 VRB] Begin request [15212170-e218-42b4-856e-1c4848fb00b1]: /umbraco/backoffice/umbracoapi/contenttype/PostSave
[00:20:49 DBG] Invoking refresher Umbraco.Cms.Core.Cache.ContentTypeCacheRefresher on local server for message type RefreshByPayload
[00:20:49 DBG] Notified RefreshOther for IContentType 16009
[00:20:49 VRB] End Request [15212170-e218-42b4-856e-1c4848fb00b1]: /umbraco/backoffice/umbracoapi/contenttype/PostSave (27282.8581ms)
I can live with this, if it is taking 25 seconds-ish to refresh a content type cache.
But I'm now out of my depth here in terms of what this is actually doing under the hood.
My gut feeling is it is fine, because I am not using the strongly typed models and I want to turn models builder off anyway. But I would love to know if anyone has worked on this aspect of Umbraco before, if they had any insight on this?
I raised an issue for this, because I believe it is a bug.
I understand that the whole cache needs to be rebuilt when the models are all recompiled, but when models builder is set to Nothing, the full cache rebuild should not be required, but it is still happening.
I can confirm that we have the same slow save issue on Umbraco 11 running as an Azure Web service (P2V2) and with Azure SQL (50 DTU Std.).
Pressing the 'Save' button on a document type makes it spin for 20 - 30 seconds and it is the PostSave call that hangs for all that time before it returns.
This a screenshot of the network tab in Firefox Dev. tools:
This is a small page with less than 50 document types and less than 200 documents.
When I run our page local on my machine in VS 2022 connecting to a local MS SQL running on premise over a VPN connection, the save button spins for less than 1-2 seconds.
Its been a while now, so I cant remember the details of the above journey too clearly. However, I came across a few different causes of performance issues.
The fact that you are using DTU based service tier might be an issue for you. I have found that the DTU based model artificially throttles your queries in unexpected ways. Broadly, I think the DTU model deals well with many small queries, but when larger, slower running queries occur, the DTU limits are reached quicker and everything slows down quite significantly.
Have a look at the metrics for your database and see if the save operation is maxing out your DTUs temporarily.
OR maybe temporarily change the database to a serverless vCore based model and see if the situation improves. I think if you set it to min 0.5 and max 4 vcores, the cost wont be much different to your 50 DTU database.
Thanks for the inputs! I just checked the DTU utilization and the highest we've reached in the past 48 hours is 16%. When i hit the save button i to goes to around 2%.
I can't seem to find any metrics showing any bottlenecks. And it's only this saving of document types that is slow. All other action in the backend are snappy and responsive, this is the same for the page itself.
I have been using "uSync" for quite some time now, so any time I save a content type, its locally.
I just tried saving a few different document types in our test environment and its completely timing out for me over and over:
{"ExceptionMessage":"Execution Timeout Expired. The timeout period elapsed prior to completion of the operation or the server is not responding.\nOperation cancelled by user.\nThe statement has been terminated.","ExceptionType":null,"StackTrace":null}
The site has >100,000 nodes and >300 document types, but the document types I was saving have very few nodes created. So, It seems to me that the overall size of the site has an impact on the performance of the save. regardless of the document type.
In the PublishedSnapshotServiceEventHandler we have this:
The call to
_publishedSnapshotService.Rebuild
is the important bit.
It calls NucacheContentService.Rebuild:
So, as you can see here, it passes nulls for mediaTypeIds and memberTypeIds
In the NuCacheContentRepository, 3 more methods are called, one each for content, media and members
But in these methods, it seems that a null triggers an entire cache refresh:
So my theory is that when the upstream services are calling "Rebuild" with nulls for media type and member type ids, they are assuming that the cache will not be refreshed, but in fact the downstream services have been built to treat a null as a trigger to refresh everything.
I am going to try override this somehow and inject in arrays of:
new [] { -1 }
instead od nulls, because i believe the NuCAcheContentRepository will find no matches and therefore process no records, instead of processing the whole database.
I needed to find something I could replace with dependency injection. So I decided to remove the out-of-the-box Umbraco handler for ContentTypeRefreshedNotification.
Then I created a new Custom notification handler and added that in instead. In that handler, all i did was replace the nulls with arrays containing a single -1. It seems to be working for me and on the surface I dont think it should cause any side effects.
Ill raise a bug about it on github.
In the mean time, if you want to try it out yourself, I have the code here:
This is an extension to IUmbracoBuilder to replace the handler:
public static IUmbracoBuilder ReplacePublishedSnapshotServiceEventHandler(this IUmbracoBuilder builder)
{
while (builder.Services.Any(descriptor => descriptor.ServiceType == typeof(INotificationHandler<ContentTypeRefreshedNotification>)))
{
var serviceDescriptor = builder.Services.FirstOrDefault(descriptor => descriptor.ServiceType == typeof(INotificationHandler<ContentTypeRefreshedNotification>));
builder.Services.Remove(serviceDescriptor);
}
builder.Services.AddSingleton<CustomPublishedSnapshotServiceEventHandler>();
builder.AddNotificationHandler<ContentTypeRefreshedNotification, CustomPublishedSnapshotServiceEventHandler>();
return builder;
}
"Save" button loading forever on Azure App Service
Hi All,
I have a strange issue when I click the "Save" button to save a document type in the Backoffice. When the site is deployed to azure app service, it shows the loading icon for an extremely long time (i dont know exactly, but it feels like minutes). But if I run out of patients and refresh the window after, say 10 seconds, the changes have actually been persisted even though the button hasn't stopped loading.
When I inspect the network tab, I can see that the PostSave call is eventually getting a gateway timeout on the azure app service, which enables the save button again and shows a back office error. But again, the changes are actually persisted.
When I run the site locally this does not happen. Even when I point my local environment at the same Azure database that the app service uses. So I don't think its a database performance issue.
There is also another behaviour I have seen on application startup that might be related. Locally, the application starts in a few seconds (even when pointed at the Azure database the app service uses). But on the Azure App Service itself, it takes several minutes to start. At a guess, Id say between 5 and 10 minutes.
Any ideas what could be causing this?
FYI, I am using the latest version 9, but this has been happening for some time through all the various RCs and nightly builds
Are you load balanced (i.e. multi-Umbraco-instance)? And even if not, have you configured the server role(s) correctly (single/publisher/subscriber)?
Are you multi-Azure-app-instance?
Are you using Azure SQL or SQL Server or something else?
Are you using uSync?
Which model builder mode are you on?
We haven't deployed a v9 site to Azure yet (only v8), but we run all our Umbracos as load balanced Azure App Services (using SQL Server on an Azure VM on the same internal network) and don't have this problem.
Thanks for the replies guys. Sorry if I didn't give enough info:
This is our test environment. Its running P2V2 (7GB memory, 420ACU)
No, I cant see a CPU spike when saving, nor anything significant while starting up either.
It happens on all document types as far as I can tell. Some with as few as 1 document using it. Many of my document types are elements used within blocklists. Not sure if that would make a difference?
S4 and utilisation never goes above 3 or 4%
Nothing. But ill try increase the log level and see if I see anything else.
I'm running this on an app service and the app service plan is set not to scale for the moment, so it will only be one instance, but still, you make an interesting point, there are extra network layers that I wont have locally. Let me have a read of the multi-intance documentation and see if there is anything in that.
No
Yeah, i have had problems with DTU throttling on Azure SQL Databases in the past when running complex queries, which you dont see on SQL server running on a VM. But I see no evidence of that here because all the utilisation charts are very low.
And just to clarify, you are using the same Umbraco instance for Admin (i.e. Umbraco) and Front-end?
Yes.
But perhaps I have caused an issue by connecting to the Azure Db from my local environment? I mean, I occasionally connect to the "test environment" azure database from my local machine. So effectively there are 2 instances of the Backoffice using the same Db. I havent had a chance to read the docs about multi-instance, but could that be an issue? But in saying that, if it was an issue, you would expect to see weird behaviour on both Backoffices, but I dont. Just the one hosted on Azure app service.
Its running on Linux too, and my local machine is Windows.
Hi All,
When I increase the log level on the server, I get the following when I save a document type:
Which seems to then trigger a rake load of these log entries (over 5000, so i think its every node on the site):
Which, on the face of it seems a bit fishy. But according to the timestamps of the logs and the timing messages, it takes less than a second to complete:
And Id assume that these kinds of thing don't run interactively anyway, right? I mean, I assume if there is some sort of cache re-building going on, it wouldn't block the back office requests.
It does sound unrelated.
So,
PostSavenever gets a response from the Umbraco back office APIs, and gets a "gateway timeout" when ARR(?) has timed outCan you show the "gateway timeout" error, and any strange requests/response before/after? This looks like a communication failure between the web UI and
PostSave, so something strictly Azure-infrastructure-related, or web app configuration related.Thanks for your response again.
Yeah, correct. If I wait a couple of seconds and then reload the browser after clicking save, the changes have persisted.
It does feel like a network-y type of issue to me. I cant find any evidence of a performance bottleneck. I have not changed any settings on the app services relating to networking. Its an off-the-shelf .net 5 linux app service, with the deployment centre hooked up to a repo. Thats it.
There are no other network requests going on when I get the gateway timeout. Except this request that polls, but again, this seems normal:
/umbraco/backoffice/umbracoapi/authentication/GetRemainingTimeoutSeconds
The response itself is also pretty uneventful
We have a couple of custom middlewares. I'm going to recheck them for any silly typos with async/await.
I might also try deploy to a windows server and see if its the same behaviour
So I deployed the same code to a Windows appservice and I get the same behaviour.
I think the next step might be to deploy a fresh V9 install, with no customisations and see if that has the same behaviour.
I think I have discovered the issue. I have been working locally a lot more lately, migrating a large amount of data onto the new Umbraco site and I started seeing this behaviour locally too.
Locally, I was able to wait for the server to eventually respond (I obviously don't get the gateway timeout locally) and I could see that our earlier assumptions about the cache building being in a background job were incorrect. The sever eventually responded after the cache building has finished (after like 3 or 4 minutes).
So I started having a look at the source code in this area and I found this comment in PublishedSnapshotService.cs
originating from this fix:
https://github.com/umbraco/Umbraco-CMS/pull/5767/commits/126c4cbd46de303bd3cf6ca095d68216d16f914a
So, it seems when you have models builder set to "InMemoryAuto", the caches are rebuilt on the interactive thread. And because I have over 100k documents, its taking several minutes to do this.
It sounds like the simple solution is to change the models builder configuration to another option than "InMemoryAuto", which I will try. But peeking around at the code, Im not sure it will change anything.
The caches are rebuild if this is true:
and the source of this method is:
So according to this, it will always return true, unless the factory is an instance of IAutoPublishedModelFactory. In which case it returns
factory.Enabled.BUT
It looks like there is only one implementation of this interface:
and for
factory.Enabledit uses this:
And it is only used if "InMemoryAuto" is enabled:
So, basically, this is always going to happen, regardless of the models builder config.
Because if i dont set it to "inMemoryAuto" i fall into the else block from earlier "// if it's not ILivePublishedModelFactory we can't determine if it's enabled or not so return true" and if I DO set it to "inMemoryAuto", true is always returned.
I hope I am missing something, but I'll try this out and see what the behaviour is in testing.
So, just to be clear, when you save a document type in development it takes 3-4 minutes with 100k documents? That sounds insane. I've never seen document type save times above a few seconds.
Why would the number of documents matter? It seems like only the amount of document types should matter? How many document types do you have?
Perhaps there is something in your solution that increases the cache rebuild time dramatically?
Other than that, fantastic investigation. Following with great curiousity. :) And it's disappointing that Occam's razor strikes again; the timeout occurred because the save actually did time out.
I think the reason the number of documents matters is because when it forces a cache refresh, it queries all the content, all >100k records, creates a new IPublishedContent for each of them and then saves them all into the content cache. Then it does the same for the media.
The document type save works in a second or two, like you say. It does actually persist the changes. But it looks like it triggers a cache rebuild (which take a few minutes) before it returns a response back to the browser.
I changed to another models builder mode: SourceCodeAuto
Same behaviour.
I figure that the implementation of the
IPublishedModelFactorythat the site uses needs to implementIAutoPublishedModelFactorybut also return false for theEnabledproperty of theIAutoPublishedModelFactoryinterface, if I want to turn off this auto cache re-build (see the logic in the posts above).There is no implementation like this in the source code. Its my opinion that if I set
I should get an implementation injected as i described above. But i dont. I get the
NoopPublishedModelFactorywhich does not implementIAutoPublishedModelFactory.So I made my own one:
and added it to the serivces after removing all other implementations:
Now, when I save a doc type, it doesnt take 3 to 4 minutes and spew out hundreds of thousands of logs, it takes about 25 seconds. and the logs look like this:
I can live with this, if it is taking 25 seconds-ish to refresh a content type cache.
But I'm now out of my depth here in terms of what this is actually doing under the hood.
My gut feeling is it is fine, because I am not using the strongly typed models and I want to turn models builder off anyway. But I would love to know if anyone has worked on this aspect of Umbraco before, if they had any insight on this?
I raised an issue for this, because I believe it is a bug. I understand that the whole cache needs to be rebuilt when the models are all recompiled, but when models builder is set to Nothing, the full cache rebuild should not be required, but it is still happening.
https://github.com/umbraco/Umbraco-CMS/issues/11409
I can confirm that we have the same slow save issue on Umbraco 11 running as an Azure Web service (P2V2) and with Azure SQL (50 DTU Std.).
Pressing the 'Save' button on a document type makes it spin for 20 - 30 seconds and it is the PostSave call that hangs for all that time before it returns.
This a screenshot of the network tab in Firefox Dev. tools: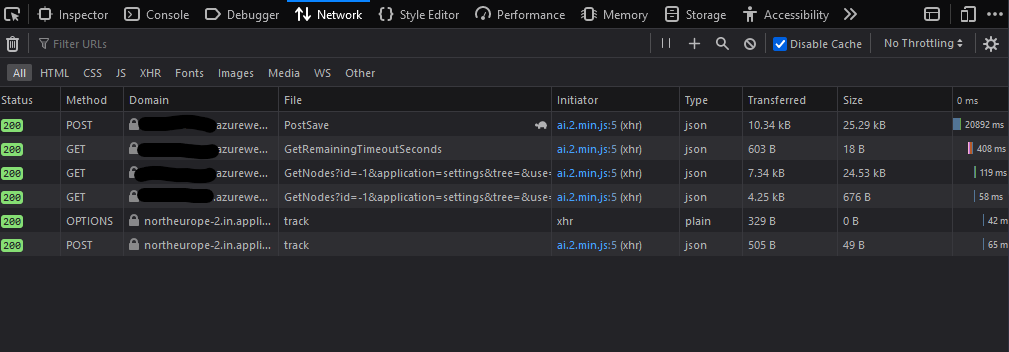
This is a small page with less than 50 document types and less than 200 documents.
When I run our page local on my machine in VS 2022 connecting to a local MS SQL running on premise over a VPN connection, the save button spins for less than 1-2 seconds.
Hi Kare Mai,
Its been a while now, so I cant remember the details of the above journey too clearly. However, I came across a few different causes of performance issues.
The fact that you are using DTU based service tier might be an issue for you. I have found that the DTU based model artificially throttles your queries in unexpected ways. Broadly, I think the DTU model deals well with many small queries, but when larger, slower running queries occur, the DTU limits are reached quicker and everything slows down quite significantly.
Have a look at the metrics for your database and see if the save operation is maxing out your DTUs temporarily. OR maybe temporarily change the database to a serverless vCore based model and see if the situation improves. I think if you set it to min 0.5 and max 4 vcores, the cost wont be much different to your 50 DTU database.
Hi Keith,
Thanks for the inputs! I just checked the DTU utilization and the highest we've reached in the past 48 hours is 16%. When i hit the save button i to goes to around 2%.
I can't seem to find any metrics showing any bottlenecks. And it's only this saving of document types that is slow. All other action in the backend are snappy and responsive, this is the same for the page itself.
Oh, wow, its happening to me too! (V10.0.0)
I have been using "uSync" for quite some time now, so any time I save a content type, its locally.
I just tried saving a few different document types in our test environment and its completely timing out for me over and over:
The site has >100,000 nodes and >300 document types, but the document types I was saving have very few nodes created. So, It seems to me that the overall size of the site has an impact on the performance of the save. regardless of the document type.
I think I have found something.
In the PublishedSnapshotServiceEventHandler we have this:
The call to
is the important bit. It calls NucacheContentService.Rebuild:
So, as you can see here, it passes nulls for mediaTypeIds and memberTypeIds
In the NuCacheContentRepository, 3 more methods are called, one each for content, media and members
But in these methods, it seems that a null triggers an entire cache refresh:
So my theory is that when the upstream services are calling "Rebuild" with nulls for media type and member type ids, they are assuming that the cache will not be refreshed, but in fact the downstream services have been built to treat a null as a trigger to refresh everything.
I am going to try override this somehow and inject in arrays of:
new [] { -1 }
instead od nulls, because i believe the NuCAcheContentRepository will find no matches and therefore process no records, instead of processing the whole database.
Christ, i think it has worked.
I needed to find something I could replace with dependency injection. So I decided to remove the out-of-the-box Umbraco handler for ContentTypeRefreshedNotification.
Then I created a new Custom notification handler and added that in instead. In that handler, all i did was replace the nulls with arrays containing a single -1. It seems to be working for me and on the surface I dont think it should cause any side effects.
Ill raise a bug about it on github.
In the mean time, if you want to try it out yourself, I have the code here:
This is an extension to IUmbracoBuilder to replace the handler:
Call this from startup like this:
The code for the actual handler itself is here:
is working on a reply...
This forum is in read-only mode while we transition to the new forum.
You can continue this topic on the new forum by tapping the "Continue discussion" link below.