Full Text Search doesnot support to search chinese texts
Hi,
I have installed andf implemented Full Text Search 6.12 for website with umbraco 6.1.3. But it doesnot help me to search Chinese texts, neither simple nor trational chinese. Does it support Unicode or where is Setting for that?
You will need to use chinese analyser. You will need to in your source solution / project add reference via nuget to lucene.net contrib https://www.nuget.org/packages/Lucene.Net.Contrib/2.9.4.1 then you will need to modify your examine configs to use the chinese analyser then the search will work. As far as I am aware full text search uses standard analyser which is fine for western languages but not for chinese / hebrew / arabic etc.
I have added Lucene.Net.Contrib.Analyzers.dll from 2.9.4.1 net40 in bin Folder and referenced it in ExamineSettings.config:
Then cleared and re-created all index in App_Data\TEMP\ExamineIndexes,
but as result, it found not yet any Chinese Texts at least from node name.
My Example is Website www.melnet.com with umbraco 6.1.3 and fulltextsearch 6.1.2, I use also Polyglot to get mapping system for Multilanguage.
Second problem is, fullTextSeaerch cannot find Texts from bodytext, which is set in my IndexUserfields from ExamineIndex.config, and in Parameter bodyProperties="".
Download luke for lucene https://code.google.com/archive/p/luke/downloads v3.5.0 you will need java installed. Then open the index using that and then check your fields in the index do you have chinese in there? If not then there is a problem with full txt search package and indexing chinese.
I have done chinese indexing but I did not use full text search package i wrote my own search and it all worked fine.
That is showing you the tokens. Can you click on the search tab, then from the dropdown on the right select chinese analyser and from fields drop down select body text. Next enter chinese search text and click search. Do you get results?
If you do then there is something wrong with full text search query generation you may need to step through the code and get the generated lucene query. I have not used full text search so do not know my way round it. However the source code is available to download.
ok, the indexsearch works but not works in Website:
In umbraco Full test Search query generation (Fulltextsearch.cshtml) I have nothing changed in logic, I will see how to get lucene query with lucne sytax.
You may have to step through code of partial and see if in the returned xml line 184 you have the generated query. If not you will need to step through the source code in the SearchExtension.Search method. If you can get the query and paste it back we can then see what is going on.
I'm just getting into Umbraco development and think it's awesome! :D
This is my first request for help and I appear to have the exact same issue described by Jianchun in the post above.
Ismail - I have followed your excellent advise and, like Jianchun, found that LUKE is returning matching Chinese with more than one search character results (as does the Umbraco back office)
Unfortunately, like Jianchun, I can only achieve successful search results from my index if I use only a single character.
Modified ExamineSettings.config and ExamineIndex.config accordingly (see below)
Deleted the temporary and specific Examine "index" folders
Cleaned and rebuilt the solution
Run the solution (checking that the indexes repopulated successfully)
When I search on the front-end of the site I do not get the same results as hen I use LUKE. Just to reiterate; English search queries work and also single character Chinese searches - it's bizarre!
I've noticed that Jianchun seems to have got this working now on the website at www.melnet.com so I am really keeping my fingers crossed that you can help me resolve this challenging issue.
Thanks guys,
David
PS: I also tried downloading version 3.0.3 of the Lucene.net dll but that gave me compilation errors in Visual Studio :(
Do not download 303 that wont work as it targets later vesrion of lucene and umbraco is 2.9.4. One thing are you doing wildcard on your search? if so take that off as it will not work.
Wow, seriously impressed with the response time - thank you :)
What a community!
My search code is shown below.
I've checked that the query value is passing in okay and that my search results page is using the correct indexer (it is).
I am using a value that is in the page name that is known-working in the LUKE search analyser that you recommended (which is really cool btw).
hmmm - I'm just wondering if this is because I'm not using the latest Lucene search analyser code. Which one would you recommend from the site below (or is there another source perhaps)?
https://lucenenet.apache.org
Thanks again,
David
var Searcher = Examine.ExamineManager.Instance.SearchProviderCollection[@Umbraco.GetDictionaryValue("SearchIndex")];
var searchResults = Searcher.Search(Request.QueryString["q"],true).OrderByDescending(x => x.Score).TakeWhile(x => x.Score > 0.05f);
var pageSize = 6;
var page = 1; int.TryParse(Request.QueryString["page"], out page);
var totalPages = (int)Math.Ceiling((double)searchResults.Count() / (double)pageSize);
var results = Request.QueryString["q"];
Full Text Search doesnot support to search chinese texts
Hi,
I have installed andf implemented Full Text Search 6.12 for website with umbraco 6.1.3. But it doesnot help me to search Chinese texts, neither simple nor trational chinese. Does it support Unicode or where is Setting for that?
Thanks a lot!
Jianchun
Jianchun,
You will need to use chinese analyser. You will need to in your source solution / project add reference via nuget to lucene.net contrib https://www.nuget.org/packages/Lucene.Net.Contrib/2.9.4.1 then you will need to modify your examine configs to use the chinese analyser then the search will work. As far as I am aware full text search uses standard analyser which is fine for western languages but not for chinese / hebrew / arabic etc.
Also one more thing to be aware of when using chinese analyser see https://our.umbraco.org/forum/extending-umbraco-and-using-the-api/80406-examine-query-generation-issue
Regards
Ismail
Hi Ismail,
Thanks a lot for your solution!
I have added Lucene.Net.Contrib.Analyzers.dll from 2.9.4.1 net40 in bin Folder and referenced it in ExamineSettings.config:
Then cleared and re-created all index in App_Data\TEMP\ExamineIndexes,
but as result, it found not yet any Chinese Texts at least from node name.
My Example is Website www.melnet.com with umbraco 6.1.3 and fulltextsearch 6.1.2, I use also Polyglot to get mapping system for Multilanguage.
Second problem is, fullTextSeaerch cannot find Texts from bodytext, which is set in my IndexUserfields from ExamineIndex.config, and in Parameter bodyProperties="".
Thanks a lot for your help!
Jianchun,
Can you open your index in luke and see if content has been added to the index.
Regards
Ismail
Hi ISmail,
I'm not sure what it means, if I seach new text and found, there is no change in all index folder: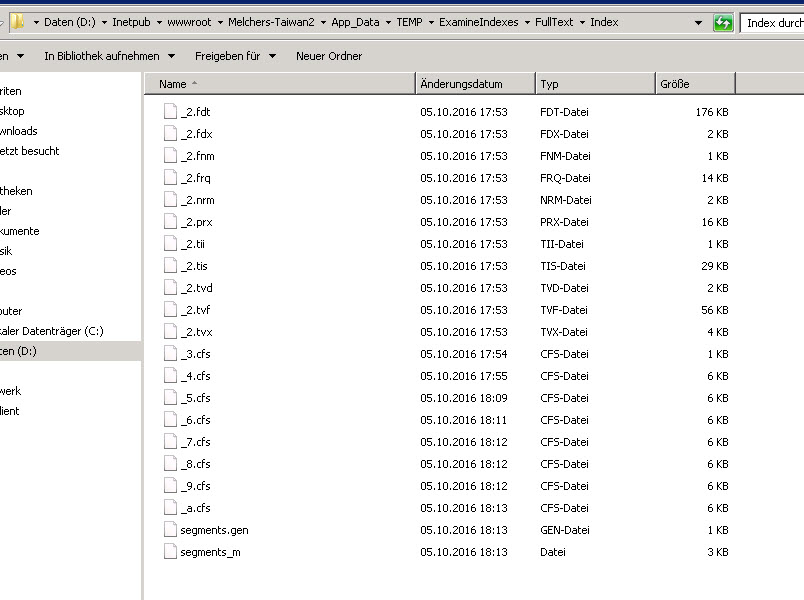
Regards
Jianchun
Download luke for lucene https://code.google.com/archive/p/luke/downloads v3.5.0 you will need java installed. Then open the index using that and then check your fields in the index do you have chinese in there? If not then there is a problem with full txt search package and indexing chinese.
I have done chinese indexing but I did not use full text search package i wrote my own search and it all worked fine.
Regards
Ismail
Hi Ismail,
Yes I see some only chinese single char in index.
Jianchun,
That is showing you the tokens. Can you click on the search tab, then from the dropdown on the right select chinese analyser and from fields drop down select body text. Next enter chinese search text and click search. Do you get results?
If you do then there is something wrong with full text search query generation you may need to step through the code and get the generated lucene query. I have not used full text search so do not know my way round it. However the source code is available to download.
Regards
Ismail
Hi Ismail,
ok, the indexsearch works but not works in Website: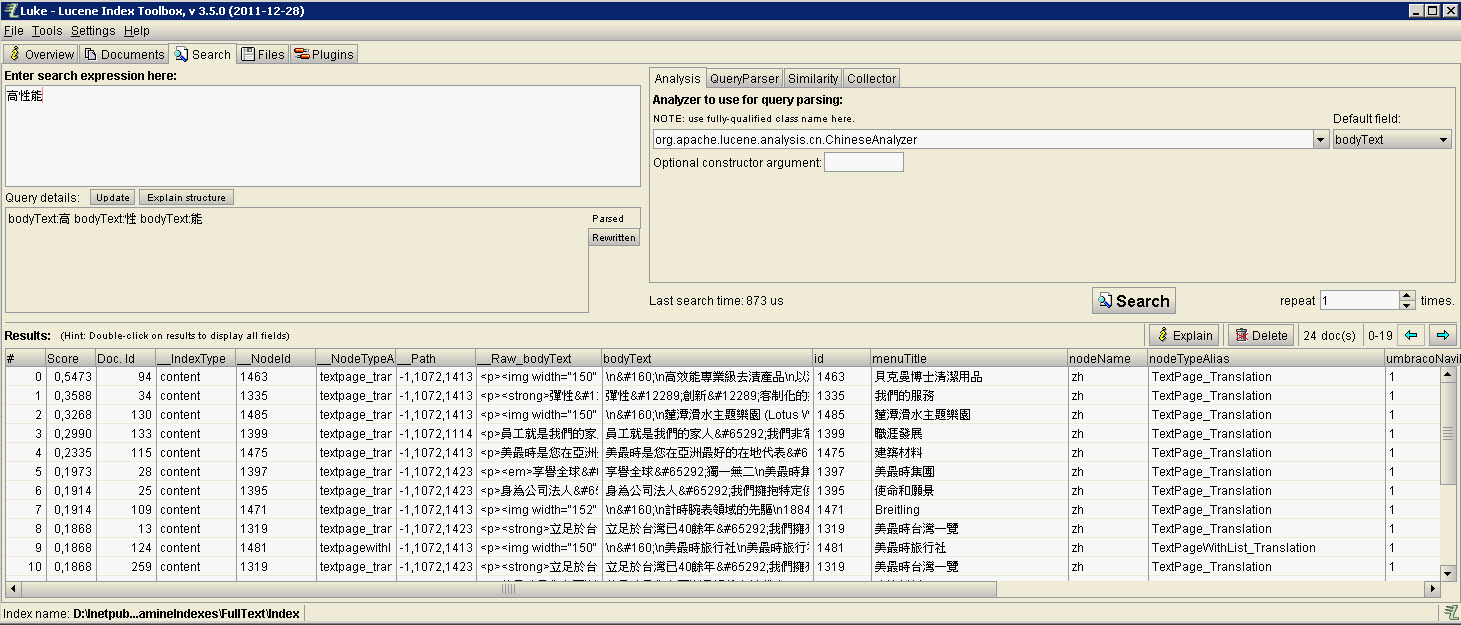
In umbraco Full test Search query generation (Fulltextsearch.cshtml) I have nothing changed in logic, I will see how to get lucene query with lucne sytax.
Thanks a lot!
Regards
-Jianchun
Jianchun,
You may have to step through code of partial and see if in the returned xml line 184 you have the generated query. If not you will need to step through the source code in the SearchExtension.Search method. If you can get the query and paste it back we can then see what is going on.
Regards
Ismail
Hi Guys,
I'm just getting into Umbraco development and think it's awesome! :D
This is my first request for help and I appear to have the exact same issue described by Jianchun in the post above.
Ismail - I have followed your excellent advise and, like Jianchun, found that LUKE is returning matching Chinese with more than one search character results (as does the Umbraco back office)
Unfortunately, like Jianchun, I can only achieve successful search results from my index if I use only a single character.
Here are the steps I have taken...
When I search on the front-end of the site I do not get the same results as hen I use LUKE. Just to reiterate; English search queries work and also single character Chinese searches - it's bizarre!
I've noticed that Jianchun seems to have got this working now on the website at www.melnet.com so I am really keeping my fingers crossed that you can help me resolve this challenging issue.
Thanks guys, David
PS: I also tried downloading version 3.0.3 of the Lucene.net dll but that gave me compilation errors in Visual Studio :(
ExamineSettings.config
ExamineIndexProvider =
ExamineSearchProvider =
ExamineIndex.config
ExamineLuceneIndexSets =
David,
Do not download 303 that wont work as it targets later vesrion of lucene and umbraco is 2.9.4. One thing are you doing wildcard on your search? if so take that off as it will not work.
Can you paste your search code please.
Regards
Ismail
Wow, seriously impressed with the response time - thank you :)
What a community!
My search code is shown below.
I've checked that the query value is passing in okay and that my search results page is using the correct indexer (it is).
I am using a value that is in the page name that is known-working in the LUKE search analyser that you recommended (which is really cool btw).
hmmm - I'm just wondering if this is because I'm not using the latest Lucene search analyser code. Which one would you recommend from the site below (or is there another source perhaps)? https://lucenenet.apache.org
Thanks again, David
Hi Ismael,
It is my search code - please my sincerest apologies.
I inherited this site from another developer and it appears that there is quite a bit of questionable code :(
I'm working through this now but can confirm that I'm managing to return Chinese results beyond a single character.
I would still like to know what the latest DLL is that should be used for Umbraco (non English) searches.
It might be an idea to host this file somewhere easier for Umbraco developers to download too.
Thank you so much buddy.
David
is working on a reply...
This forum is in read-only mode while we transition to the new forum.
You can continue this topic on the new forum by tapping the "Continue discussion" link below.