I'm sure it's something simple but it's escaping me and probably would stick out like a sore thumb to trained eyes ;-)
Here's the RTE HTML, dumbed-down to the simplest case:
<p><0.5</p>
I thought maybe if I replaced "@node.Value" with "@Html.Raw(node.Value)" in the ParseRichText() helper, that might do the trick, but it still throws the error. Also tried @node.Value.Replace("&","&") and variations.
@helper ParseRichText(XmlNodeList nodes) {
foreach(XmlNode node in nodes) {
switch(node.NodeType)
{
case XmlNodeType.Text:
@node.Value
@ParseRichText(node.ChildNodes);
break;
case XmlNodeType.Element:
@ParseElement(node);
break;
default:
@ParseRichText(node.ChildNodes);
break;
}
}
}
We have lots of data with these < ≤ ≥ and ° chars in them, and as soon as we hit one of those, it kind of runs off into the ditch when rendering in PDF.
Tried all of the suggestions above, as well as wrapping @node.Value in the helper with @Html.Raw(), but none worked. Also tried tacking .Replace() on the end of node.Value to convert < to < and &. Also tried configuring tinyMceConfig.config to use named instead of raw.
If i remove the < from the RTE, i don't get an error, but ≥ renders as Pounds Sterling char, ≤ renders as superscript 3, and > renders properly as >. Strange. Is the template not using UTF-8, maybe?
I've made a super-simple version of the template below. If you create a node (this is Umbraco 7.5.3) with a property named "assayRange" of type RTE and enter the same data shown in the images below, you should see what i'm seeing.
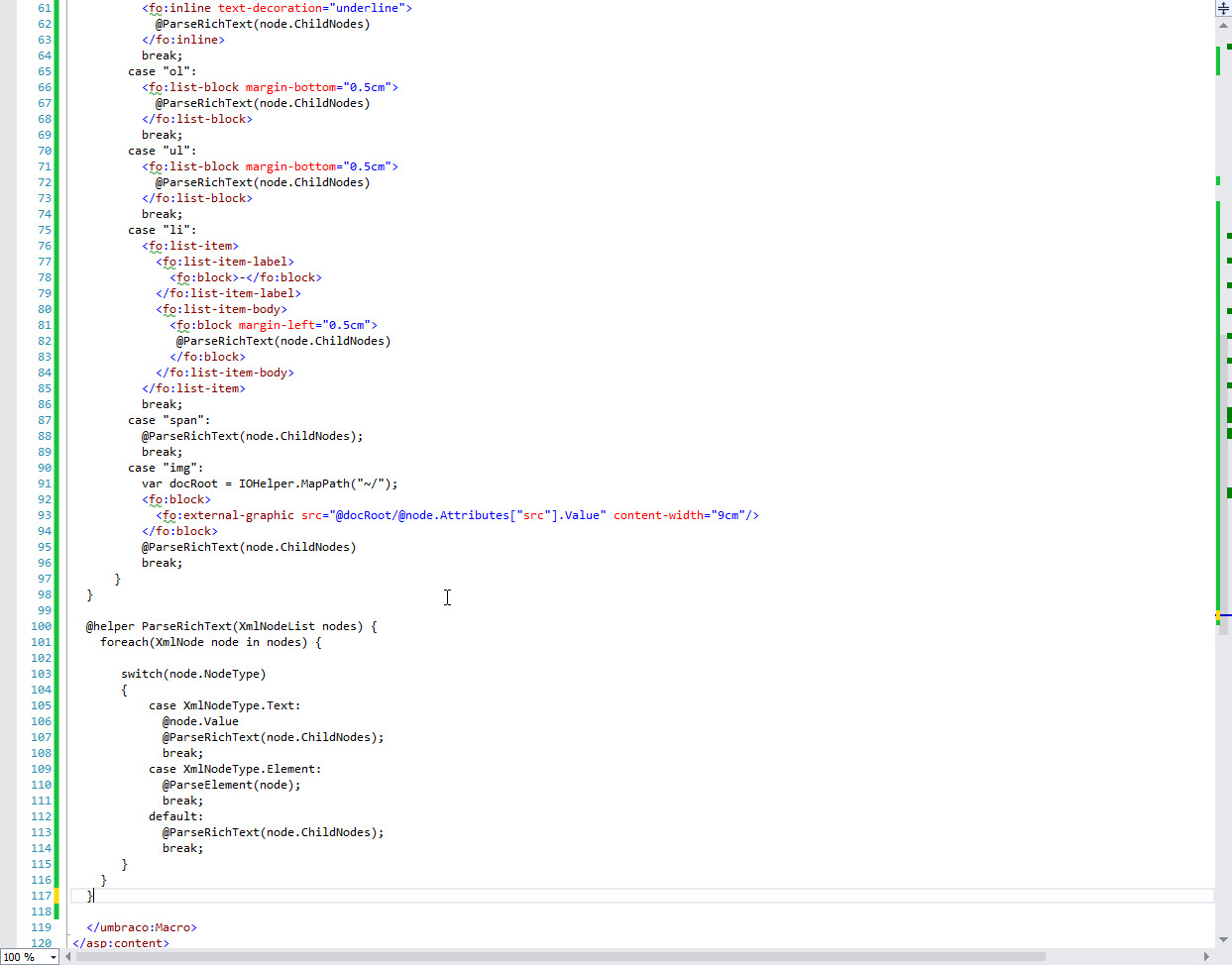
I modified the PDFRazorHelloWorld template to make this as simple as possible (see below).
Code wouldn't paste properly here in a code block or a quote, so i screen grabbed it for you to review. I'd be more than happy to email it.
Darren,
Also, for completeness, i tried simply printing out the contents of the RTE on line 30 above - it didn't render valid XSL-FO, of course, but in the raw output I could see what it was outputting.
Commending out line 11 and changing line 30 to eliminate the helper:
I'm confused - a < and > render fine on my machine but a ≥ causes an error - could you send me your template by email please? to df at darren-ferguson.com
Email sent - the template is one of the installed ones we've edited to isolate the issue, so has all the defaut parts; i've also included a screen grab of the actual test data i'm using (entered into the RTE), in both HTML and raw forms, just so we're testing the same data.
Almost there! We know that TinyMce is returning < for < and > for > when retrieved in the PDF template, as noted above. So if we change these to encoded equivalents before passing the string to GetRichTextNodes(), then those chars are correctly interpreted:
Then down in ParseRichText(), if you wrap the @node.Value so that it is @Html.Raw(node.Value), then it renders properly in PDF as the less-than and greater-than symbols.
But the other math characters, ≤ and ≥, are returned in the PDF template (@Model.assayRange in the example above) as Pounds Sterling (£) and superscript 3 (³).
I'd love to add Replace("£","&#8804;") to the line above but i can't seem to get a match on the £ symbol so that it will do the replace.
Weirder, if i were to try to do this Replace("£","&le;"), i get an error that states [Reference to undeclared entity 'le'.].
Any idea how to snag those and convert them like we did above for less-than and greater-than before passing to GetRichTextNodes()?
Darren,
Update with some progress on circumventing the errors when trying to convert <, >, ≤, and ≥
I can encode the < and > before passing to FoHelper.Instance.GetRichTextNodes() and they survive and are printed out by wrapping the @node.Value with @Html.Raw() in the ParseRichText() helper. And I’m fine with that – makes sense that we have to sneak those past GetRichTextNodes(), which is looking for start and end tags.
But what I can’t figure out is why ≤ (≤) shows up properly in the RTE but when we ask for it in the PDF template, it appears as £.
Similarly, ≥ (≥) shows up properly in the RTE but in the PDF template, it shows up as ³.
They all show up as themselves in the regular Umbraco HTML rendering of the page, it’s only inside the template when we pull the same assayRange RTE field, we get these translations.
If I could encode those to their real values (≤ and ≥), I know they’ll get through – but I can’t for the life of me figure out what those are so I could do a Replace() on them.
Please take the revised template inside the Zip and run it against the simple example and see if I need to include something else in order to get those to show up.
I do know that if I try to convert to “≤” it throws an error, so that’s why it feels like a code page issue in the template.
Wow. Solved. Our customer actually came across an article that stated that XSL-FO pulls in its own default charset, which doesn't necessarily cover those symbols (less-than-or-equal-to, greater-than-or-equal-to).
So he just added font-family: sans-serif to the <fo:block> tag and voila! It works!
==> So perhaps the issue isn't a bug in PDFCreator, per se, it's in the limited charset that XSL-FO uses? By specifying a font with support for those characters like we did here, it seems to work.
Thanks to Darren and his crew for chasing this one around. It was elusive.
Error attempting to render ≥ and other special chars in PDF
When attempting to render less-than or less-than-or-equal signs in PDF, we're getting the following error:
Those chars render correctly in the Umbraco view, but when PDFCreator outputs XSL-FO, that's when we're seeing the error.
The assayRange property is an RTE and contains HTML.
What do I need to do to get special chars to render properly in the PDF output?
What is the raw HTML of the rich text area that is causing the error?
The exception appears to be thrown by the helper that tries to read it as XML and it appears that you have an invalid tag that begins <0
If you post the HTML of the RTE, it'll probably be quite easy to spot.
Thanks.
I'm sure it's something simple but it's escaping me and probably would stick out like a sore thumb to trained eyes ;-)
Here's the RTE HTML, dumbed-down to the simplest case:
We have lots of data with these < ≤ ≥ and ° chars in them, and as soon as we hit one of those, it kind of runs off into the ditch when rendering in PDF.
I appreciate your help!
Out of interest does it work if you remove the < from the RTE. Though it is odd as the RTE has already escaped it to < which should be fine.
Also what happens if you remove @node.Value completely from the ParseRichText helper?
Also try temporarily write node.Value wrapped by System.Web.HttpUtility.HtmlEncode()
I won't have a moment until next week - but I could give it a go myself...
Tried all of the suggestions above, as well as wrapping @node.Value in the helper with @Html.Raw(), but none worked. Also tried tacking .Replace() on the end of node.Value to convert < to < and &. Also tried configuring tinyMceConfig.config to use named instead of raw.
If i remove the < from the RTE, i don't get an error, but ≥ renders as Pounds Sterling char, ≤ renders as superscript 3, and > renders properly as >. Strange. Is the template not using UTF-8, maybe?
I've made a super-simple version of the template below. If you create a node (this is Umbraco 7.5.3) with a property named "assayRange" of type RTE and enter the same data shown in the images below, you should see what i'm seeing.
I modified the PDFRazorHelloWorld template to make this as simple as possible (see below).
Code wouldn't paste properly here in a code block or a quote, so i screen grabbed it for you to review. I'd be more than happy to email it.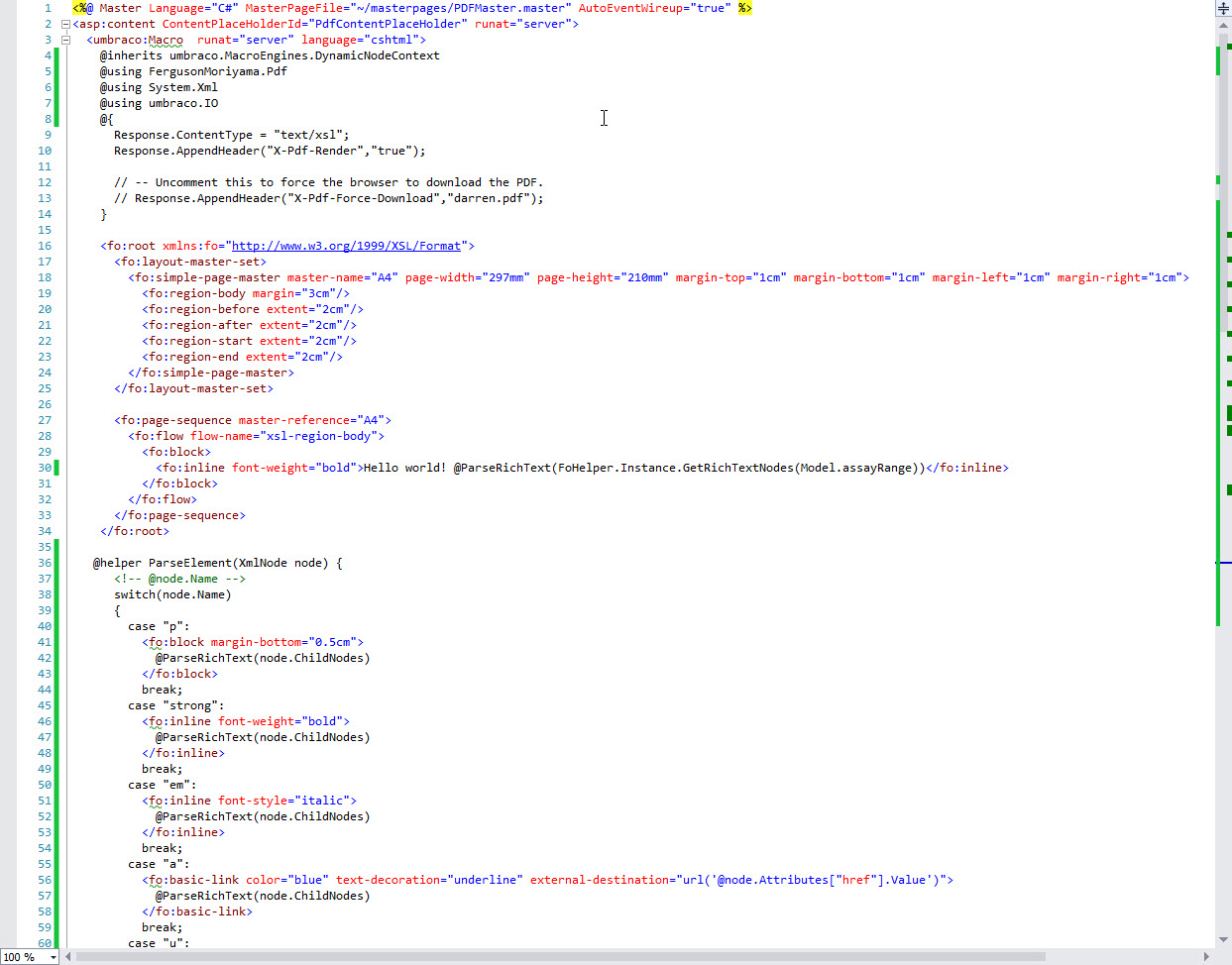
Darren, Also, for completeness, i tried simply printing out the contents of the RTE on line 30 above - it didn't render valid XSL-FO, of course, but in the raw output I could see what it was outputting.
Commending out line 11 and changing line 30 to eliminate the helper:
resulted in this raw output:
Does that make sense? Is there a directive at the top of the template that I need to add that isn't in the template above?
Really a head-scratcher.
I'm confused - a < and > render fine on my machine but a ≥ causes an error - could you send me your template by email please? to df at darren-ferguson.com
Email sent - the template is one of the installed ones we've edited to isolate the issue, so has all the defaut parts; i've also included a screen grab of the actual test data i'm using (entered into the RTE), in both HTML and raw forms, just so we're testing the same data.
edited 2016.16.11
Darren,
Almost there! We know that TinyMce is returning
<for < and>for > when retrieved in the PDF template, as noted above. So if we change these to encoded equivalents before passing the string to GetRichTextNodes(), then those chars are correctly interpreted:Then down in ParseRichText(), if you wrap the @node.Value so that it is
@Html.Raw(node.Value), then it renders properly in PDF as the less-than and greater-than symbols.But the other math characters, ≤ and ≥, are returned in the PDF template (@Model.assayRange in the example above) as Pounds Sterling (£) and superscript 3 (³).
I'd love to add Replace("
£","&#8804;") to the line above but i can't seem to get a match on the£symbol so that it will do the replace.Weirder, if i were to try to do this Replace("
£","&le;"), i get an error that states [Reference to undeclared entity 'le'.].Any idea how to snag those and convert them like we did above for less-than and greater-than before passing to GetRichTextNodes()?
Thanks.
Darren, Update with some progress on circumventing the errors when trying to convert <, >, ≤, and ≥
I can encode the < and > before passing to FoHelper.Instance.GetRichTextNodes() and they survive and are printed out by wrapping the @node.Value with @Html.Raw() in the ParseRichText() helper. And I’m fine with that – makes sense that we have to sneak those past GetRichTextNodes(), which is looking for start and end tags.
But what I can’t figure out is why ≤ (≤) shows up properly in the RTE but when we ask for it in the PDF template, it appears as £.
Similarly, ≥ (≥) shows up properly in the RTE but in the PDF template, it shows up as ³.
They all show up as themselves in the regular Umbraco HTML rendering of the page, it’s only inside the template when we pull the same assayRange RTE field, we get these translations.
If I could encode those to their real values (≤ and ≥), I know they’ll get through – but I can’t for the life of me figure out what those are so I could do a Replace() on them.
Please take the revised template inside the Zip and run it against the simple example and see if I need to include something else in order to get those to show up.
I do know that if I try to convert to “≤” it throws an error, so that’s why it feels like a code page issue in the template.
Thanks!
Wow. Solved. Our customer actually came across an article that stated that XSL-FO pulls in its own default charset, which doesn't necessarily cover those symbols (less-than-or-equal-to, greater-than-or-equal-to).
So he just added
font-family: sans-serifto the<fo:block>tag and voila! It works!So the change was from:
<fo:block font-size="9pt" color="#000">@ParseRichText(FoHelper.Instance.GetRichTextNodes(EncodeSpecialChars(@specimen.assayRange.ToString())))</fo:block>to:
<fo:block font-family="sans-serif" font-size="9pt" color="#000">@ParseRichText(FoHelper.Instance.GetRichTextNodes(EncodeSpecialChars(@specimen.assayRange.ToString())))</fo:block>==> So perhaps the issue isn't a bug in PDFCreator, per se, it's in the limited charset that XSL-FO uses? By specifying a font with support for those characters like we did here, it seems to work.
Thanks to Darren and his crew for chasing this one around. It was elusive.
is working on a reply...
This forum is in read-only mode while we transition to the new forum.
You can continue this topic on the new forum by tapping the "Continue discussion" link below.